
Oude versies Firefox gaan slechter werken door verlopen rootcertificaat - Computer - Nieuws - Tweakers
Software-update: Mozilla Firefox 136.0.1 - Computer - Downloads - Tweakers
Software-update: Mozilla Thunderbird 128.8.0esr - Computer - Downloads - Tweakers
Software-update: Mozilla Thunderbird 136.0 - Computer - Downloads - Tweakers
Mozilla: 'Nieuwe gebruiksvoorwaarden betekent niet dat wij gebruikersdata gaan verkopen' - Dutch IT Channel
Maker Firefox-browser reageert op kritiek op nieuwe gebruiksvoorwaarden - NU.nl
Mozilla: Firefox-voorwaarden geven het bedrijf geen eigendom van gebruikersdata - Computer - Nieuws - Tweakers
Firefox zegt dat het misschien je persoonlijke data verkoopt - Androidworld
What is the best hardware concurrency for running inference on CPU?
In the Firefox AI Runtime, we can use multiple threads in the dedicated inference process to speed up execution times CPU. The WASM/JS environment can create a SharedArrayBuffer and run multiple threads against its content and distribute the load on several CPU cores concurrently.
Below is the time taken in seconds on a MacBook M1 Pro, which has 10 physical cores, using our PDF.js image-to-text model to generate an alt text, with different levels of concurrency:

So running several threads is a game-changer ! But using more and more threads will start to slow down execution time to a point where it will become slower than not using threads at all.
So one question we have asked ourselves was: how can we determine the best number of threads ?
Physical vs logical coresAccording to our most recent public data report, on desktop, 81% of our users are equipped with an Intel CPU, 14% with AMD and the rest are mostly Apple devices.
All modern CPUs provide more logical cores (also called “threads”) than physical cores. This happens due to technologies like Intel’s Hyper-Threading. Or AMD’s Simultaneous Multithreading (SMT).
For example, the Intel Core i9-10900K chip has 10 physical cores and 20 logical cores.
When you spin up threads equal to the number of logical cores, you might see performance gains, especially when tasks are I/O bound or if the CPU can effectively interleave instructions.
However, for compute-bound tasks (like heavy ML inference), having more threads than physical cores can lead to diminishing returns, or even performance drops, due to factors like thread scheduling overhead and cache contention.
Not all cores are created equalOn Apple Silicon, you don’t just have a quantity of cores; you have different kinds of cores. Some are high-performance cores designed for heavy lifting, while others are efficiency cores that are optimized for lower power consumption.
For instance, Apple M1 Pro chips have a combination of high-performance (8) and efficiency cores (2). The physical cores might total 10, but each performance core is designed for heavy-duty tasks, while efficiency cores typically handle background tasks that are less demanding.
When your machine is under load with ML tasks, it’s often better to fully utilize the high-performance cores and leave some breathing room for the efficiency cores to handle background or system processes.
Similarly, Intel’s processors have different cores, most notably starting with their 12th-generation “Alder Lake” architecture.
These chips feature Performance-cores (P-cores) designed for demanding, single-threaded tasks, and Efficient-cores (E-cores) aimed at background or less intensive workloads. The P-cores can leverage Intel’s Hyper-Threading technology (meaning each P-core can run two logical threads), while E-cores typically run one thread each. This hybrid approach enables the CPU to optimize power usage and performance by scheduling tasks on the cores best suited for them. Like Apple Silicon’s you’d typically want to maximize utilization of the higher-performance P-cores, while leaving some headroom on the E-cores for system processes.
Android is close to Apple Silicon’s architecture, as most devices are using ARM’s big.LITTLE (or DynamIQ) architecture – with 2 types of cores: “big” and “LITTLE”.
On mobile Qualcomm’s CPU, there can be three types: “Prime”, “Performance” and “Efficiency”. Most recently, some phones like Samsung Galaxy S24 have gained a fourth kind of core (Exynos 2400) allowing even more combinations.
To summarize, all CPU makers have cores dedicated to performance, and cores for efficiency:
- Performance: “P-Core”, “big”, “Prime”, “Performance”
- Efficiency: “E-Core”, “LITTLE”, “Efficiency”
By combining high-efficiency and high-performance cores, Apple Silicon, Androids, and Intel based devices can strike a better balance between power consumption and raw compute power, depending on the demands of the workload.
But if you try to run all cores (performance + efficiency) at maximum capacity, you may see:
- Less optimal thread scheduling, because tasks will bounce between slower efficiency cores and faster performance cores.
- Contention for shared resources like the memory bus, cache.
- And in extreme cases: thermal throttling if the system overheats, and reaches its Thermal Design Point, in which case the clock speed is throttled to cool down the system.
This is why simply setting the thread count to “all cores, all the time” can be suboptimal for performance.
AMD on the other hand, does not have efficiency cores. Some CPUs like the Ryzen 5 8000 combine two sizes of cores Zen 4 and Zen 4c, but the latter is not an efficiency core and can also be used to run heavy-duty tasks.
navigator.hardwareConcurrencyIn a browser, there is a single and simple API you can call: navigator.hardwareConcurrency
This returns the number of logical cores available. Since it’s the only API available on the web, many libraries (including the one we vendor: onnxruntime) default to using navigator.hardwareConcurrency as a baseline for concurrency.
It’s bad practice to use that value directly as it might overcommit threads as we’ve explained in the previous sections. It’s also not aware of the current system’s activity.
For that reason, ONNX formula takes the number of logical cores divided by two and will never set it higher than 4:
Math.min(4, Math.ceil((navigator.hardwareConcurrency || 1) / 2));That formula works out ok in general, but will not take advantage of all the cores for some devices. For instance, on an Apple M1 Pro, ML tasks could use a concurrency level up to 8 cores instead of 4.
On the other end of the spectrum, a chip like Intel’s i3-1220p that we use in our CI to run tests in Windows 11, which reflects better what our users have – see our hardware section in our Firefox Public Data Report.
It has 12 logical cores and 10 physical cores that are composed of 8 efficient cores and 2 performance cores. ONNX formula for that chip means we would run with 4 threads, where 2 would be a better value.
navigator.hardwareConcurrency is a good starting point, but it’s just a blunt instrument. It won’t always yield the true “best” concurrency for a given device and a given workload.
MLUtils.getOptimalCPUConcurrencyWhile it’s impossible to get the best value at any given time without considering the system activity as a whole, looking at the number of physical cores and not using “efficiency” cores, can help to get to a better value.
Llama.cpp for instance is looking at the number of physical cores to decide for concurrency, with a few twists:
- On any x86_64, it will return the number of performance cores
- On Android, and any aarch64-based devices like Apple Silicon it will return the number of performance cores for tri-layered chips.
We’ve implemented something very similar in a C++ API that can be used via XPIDL in our inference engine:
NS_IMETHODIMP MLUtils::GetOptimalCPUConcurrency(uint8_t* _retval) { ProcessInfo processInfo = {}; if (!NS_SUCCEEDED(CollectProcessInfo(processInfo))) { return NS_ERROR_FAILURE; } #if defined(ANDROID) // On android, "big" and "medium" cpus can be used. uint8_t cpuCount = processInfo.cpuPCount + processInfo.cpuMCount; #else # ifdef __aarch64__ // On aarch64 (like macBooks) we want to avoid efficient cores and stick with "big" cpus. uint8_t cpuCount = processInfo.cpuPCount; # else // on x86_64 we're always using the number of physical cores. uint8_t cpuCount = processInfo.cpuCores; # endif #endif *_retval = cpuCount; return NS_OK; }This function is then straightforward to use from JS shipped within Firefox to configure concurrency when we run inference:
let mlUtils = Cc["@mozilla.org/ml-utils;1"].createInstance(Ci.nsIMLUtils); const numThreads = mlUtils.getOptimalCPUConcurrency();We’ve moved away from using navigator.hardwareConcurrency, and we’re now using this new API.
ConclusionIn our quest to find the optimal number of threads, we’re closer to reality now, but there are other factors to consider. The system will use the CPU for other applications so it’s still possible to overload it.
Using more threads is also going to use more memory in our WASM environment, which can become a real issue. Depending on the workload, each additional thread can add up to 100MiB of physical memory usage in our runtime. We’re working on reducing this overhead but on devices that don’t have a lot of memory, limiting concurrency is still our best option.
For our Firefox ML features, we are using a variety of hardware profiles in our performance CI to make sure that we try them on devices that are close to what our users have. The list of devices we have is going to grow in the next few months to make sure we cover the whole spectrum of CPUs. We’ve started collecting and aggregating metrics on a dashboard that helps us understand what can be expected when our users run our inference engine.
The hardware landscape is also evolving a lot. For example, the most recent Apple devices introduced a new instruction set, called AMX, which used to be proprietary, and gave a significant boost compared to Neon. That has now been replaced by an official API called SME. Similarly, some phones are getting more core types, which could impact how we calculate the number of cores to use. Our current algorithm could be changed the day we leverage these new APIs and hardware in our backend.
Another aspect we have not discussed in this post is using GPU or even more specialized units like NPUs, to offload our ML tasks, which will be a post on its own.
The post What is the best hardware concurrency for running inference on CPU? appeared first on The Mozilla Blog.
Paris AI Action Summit: A milestone for open and Public AI
As we close out the Paris AI Action Summit, one thing is clear: the conversation around open and Public AI is evolving—and gaining real momentum. Just over a year ago at Bletchley Park, open source AI was framed as a risk. In Paris, we saw a major shift. There is now a growing recognition that openness isn’t just compatible with AI safety and advancing public interest AI—it’s essential to it.
We have been vocal supporters of an ecosystem grounded in open competition and trustworthy AI —one where innovation isn’t walled off by dominant players or concentrated in a single geography. Mozilla, therefore, came to this Summit with a clear and urgent message: AI must be open, human-centered, and built for the public good. And across discussions, that message resonated.
Open source AI is entering the conversation in a big wayTwo particularly notable moments stood out:
- European Commission President Ursula von der Leyen spoke about Europe’s “distinctive approach to AI,” emphasizing collaborative, open-source solutions as a path forward.
- India’s Prime Minister Narendra Modi reinforced this vision, calling for open source AI systems to enhance trust and transparency, reduce bias, and democratize technology.
These aren’t just words. The investments and initiatives announced at this Summit mark a real turning point. From the launch of Current AI, an initial $400M public interest AI partnership supporting open source development, to ROOST, a new nonprofit making AI safety tools open and accessible, to the €109 billion investment in AI computing infrastructure announced by President Macron, the momentum is clear. Add to that strong signals from the EU and India, and this Summit stands out as one of the most positive and proactive international gatherings on AI so far.
At the heart of this is Public AI—the idea that we need infrastructure beyond private, purely profit-driven AI. That means building AI that serves society and promotes true innovation even when it doesn’t fit neatly into short-term business incentives. The conversations in Paris show that we’re making progress, but there’s more work to do.
Looking ahead to the next AI summitMomentum is building, and we must forge onward. The next AI Summit in India will be a critical moment to review the progress on these announcements and ensure organizations like Mozilla—those fighting for open and Public AI infrastructure—have a seat at the table.
Mozilla is committed to turning this vision into reality—no longer a distant, abstract idea, but a movement already in motion.
A huge thanks to the organizers, partners, and global leaders driving this conversation forward. Let’s keep pushing for AI that serves humanity—not the other way around.
––Mitchell Baker
Chairwoman, Mozilla
Paris AI Action Summit Steering Committee Member
The post Paris AI Action Summit: A milestone for open and Public AI appeared first on The Mozilla Blog.
ROOST: Open source AI safety for everyone
Today we want to point to one of the most exciting announcements at the Paris AI summit: the launch of ROOST, a new nonprofit to build AI safety tools for everyone.

ROOST stands for Robust Open Online Safety Tools, and it’s solving a clear and important problem: many startups, nonprofits, and governments are trying to use AI responsibly every day but they lack access to even the most basic safety tools and resources that are available to large tech companies. This not only puts users at risk but slows down innovation. ROOST has backing from top tech companies and philanthropies alike ensuring that a broad set of stakeholders have a vested stake in its success. This is critical to building accessible, scalable and resilient safety infrastructure all of us need for the AI era.
What does this mean practically? ROOST is building, open sourcing and maintaining modular building blocks for AI safety, and offering hands-on support by technical experts to enable organizations of all sizes to build and use AI responsibly. With that, organizations can tackle some of the biggest safety challenges such as eliminating child sexual abuse material (CSAM) from AI datasets and models.
At Mozilla, we’re proud to have helped kickstart this work, providing a small seed grant for the research at Columbia University that eventually turned into ROOST. Why did we invest early? Because we believe the world needs nonprofit public AI organizations that at once complement and serve as a counterpoint to what’s being built inside the big commercial AI labs. ROOST is exactly this kind of organization, with the potential to create the kind of public technology infrastructure the Mozilla, Linux, and Apache foundations developed in the previous era of the internet.
Our support of ROOST is part of a bigger investment in open source AI and safety.
In October 2023, before the AI Safety Summit in Bletchley Park, Mozilla worked with Professor Camille Francois and Columbia University to publish an open letter that stated “when it comes to AI Safety and Security, openness is an antidote not a poison.”
Over 1,800 leading experts and community members signed our letter, which compelled us to start the Columbia Convening series to advance the conversation around AI, openness, and safety. The second Columbia Convening (which was an official event on the road to the French AI Action Summit happening this week), brought together over 45 experts and builders in AI to advance practical approaches to AI safety. This work helped shape some of the priorities of ROOST and create a community ready to engage with it going forward. We are thrilled to see ROOST emerge from the 100+ leading AI open source organizations we’ve been bringing together the past year. It exemplifies the principles of openness, pluralism, and practicality that unite this growing community.
Much has changed in the last year. At the Bletchley Park summit, a number of governments and large AI labs had focused the debate on the so-called existential risks of AI — and were proposing limits on open source AI. Just 15 months later, the tide has shifted. With the world gathering at the AI Action Summit in France, countries are embracing openness as a key component of making AI safe in practical development and deployment contexts. This is an important turning point.
ROOST launches at exactly the right time and in the right place, using this global AI summit to gather a community that will create the practical building blocks we need to enable a safer AI ecosystem. This is the type of work that makes AI safety a field that everyone can shape and improve.
The post ROOST: Open source AI safety for everyone appeared first on The Mozilla Blog.
Mozilla Localization (L10N): L10n report: January 2025 Edition
Please note some of the information provided in this report may be subject to change as we are sometimes sharing information about projects that are still in early stages and are not final yet.
Welcome!Are you a locale leader and want us to include new members in our upcoming reports? Contact us!
New content and projects What’s new or coming up in Firefox desktop Tab GroupsTab groups are now available in Nightly 136! To create a group in Nightly, all you have to do is have two tabs open, click and drag one tab to the other, pause a sec and then drop. From there the tab group editor window will appear where you can name the group and give it a color. After saving, the group will appear on your tab bar.

Once you create a group, you can easily access your groups from the overflow menu on the right.

These work great in the sidebar and vertical tabs feature that was released in the Firefox Labs feature in Nightly 131!
New profile selectorThe new profile selector which we have been localizing over the previous months is now starting to roll out gradually to users in Nightly 136. SUMO has an excellent article about all the new changes which you can find here.
What’s new or coming up in web projects AMO and AMO FrontendThe team is planning to migrate/copy the Spanish (es) locale into four: es-AR, es-CL, es-ES, and es-MX. Per the community managers’ input, all locales will retain the suggestions that have not been approved at the time of migration. Be on the lookout for the changes in the upcoming week(s).
Mozilla AccountsThe Mozilla accounts team recently landed strings used in three emails planned to be sent over the course of 90 days, with the first happening in the coming weeks. These will be sent to inactive users who have not logged in or interacted with the Mozilla accounts service in 2 years, letting them know their account and data may be deleted.
What’s new or coming up in SUMOThe CX team is still working on 2025 planning. In the meantime, read a recap from our technical writer, Lucas Siebert about how 2024 went in this blog post. We will also have a community call coming up on Feb 5th at 5 PM UTC. Check out the agenda for more detail and we’d love to see you there!
Last but not least, we will be at FOSDEM 2025. Mozilla’s booth will be at the K building, level 1. Would love to see you if you’re around!
What’s new or coming up in Pontoon New Email FeaturesWe’re excited to announce two new email features that will keep you better informed and connected with your localization work on Pontoon:
Email Notifications: Opt in to receive notifications via email, ensuring you stay up to date with important events even when you’re away from the platform. You can choose between daily or weekly digests and subscribe to specific notification types only.
Monthly Activity Summary: If enabled, you’ll receive an email summary at the start of each month, highlighting your personal activity and key activities within your teams for the previous month.
Visit your settings to explore and activate these features today!
New Translation Memory tools are here!If you are a locale manager or translator, here’s what you can do from the new TM tab on your team page:
- Search, edit, and delete Translation Memory entries with ease.
- Upload .TMX files to instantly share your Translation Memories with your team.
These tools are here to save you time and boost the quality of suggestions from Machinery. Dive in and explore the new features today!

Feedback, support and conversations on new Pontoon developments have moved from Discourse to GitHub Discussions. See you there!
Newly published localizer facing documentation- How to test mozilla.org was updated to reflect some of the changes to the site in the last year or so.
Come check out our end of year presentation on Pontoon! A Youtube link and AirMozilla link are available.
Want to showcase an event coming up that your community is participating in? Contact us and we’ll include it.
Friends of the LionKnow someone in your l10n community who’s been doing a great job and should appear here? Contact us and we’ll make sure they get a shout-out!
Useful Links- #l10n-community channel on Element (chat.mozilla.org)
- Localization category on Discourse
- Mastodon
- L10n blog
If you want to get involved, or have any question about l10n, reach out to:
- Francesco Lodolo (flod) – Engineering Manager
- Bryan – l10n Project Manager
- Delphine – l10n Project Manager for mobile
- Peiying (CocoMo) – l10n Project Manager for mozilla.org, marketing, and legal
- Francis – l10n Project Manager for Common Voice, Mozilla Foundation
- Théo Chevalier – l10n Project Manager for Mozilla Foundation
- Matjaž (mathjazz) – Pontoon dev
- Eemeli – Pontoon, Fluent dev
Did you enjoy reading this report? Let us know how we can improve it.
Firefox Nightly: Firefox on macOS: now smaller and quicker to install!
Firefox is typically installed on macOS by downloading a DMG (Disk iMaGe) file, and dragging the Firefox.app into /Applications. These DMG files are compressed to reduce download time. As of Firefox 136, we’re making an under the hood change to them, and switching from bzip2 to lzma compression, which shrinks their size by ~9% and cuts decompression time by ~50%.
Why now?If you’re familiar with macOS packaging, you’ll know that LZMA support was introduced in macOS 10.15, all the way back in 2015. However, Firefox continued to support older versions of macOS until Firefox 116.0 was released in August 2023, which meant that we couldn’t use it prior to then.
But that still begs the question: why wait ~18 months later to realize these improvements? Answering that question requires a bit of explanation of how we package Firefox…
Packaging Firefox for macOS… on Linux!Most DMGs are created with hdiutil, a standard tool that ships with macOS. hdiutil is a fine tool, but unfortunately, it only runs natively on macOS. This a problem for us, because we package Firefox thousands of times per day, and it is impractical to maintain a fleet of macOS machines large enough to support this. Instead, we use libdmg-hfsplus, a 3rd party tool that runs on Linux, to create our DMGs. This allows us to scale these operations as much as needed for a fraction of the cost.
Why now, reduxUntil recently, our fork of libdmg-hfsplus only supported bzip2 compression, which of course made it impossible for us to use lzma. Thanks to some recent efforts by Dave Vasilevsky, a wonderful volunteer who previously added bzip2 support, it now supports lzma compression.
We quietly enabled this for Firefox Nightly in 135.0, and now that it’s had some bake time there, we’re confident that it’s ready to be shipped on Beta and Release.
Why LZMA?DMGs support many types of compression: bzip2, zlib, lzfse and lzma being the most notable. Each of these has strengths and weaknesses:
- bzip2 has the best compression (in terms of size) that is supported on all macOS versions, but the slowest decompression
- zlib has very fast decompression, at the cost of increased package size
- lzfse has the fastest decompression, but the second largest package size
- lzma has the second fastest decompression and the best compression in terms of size, at the cost of increased compression times
With all of this in mind, we chose lzma to make improvements on both download size and installation time.
You may wonder why download size is an important consideration, seeing as fast broadband connections are common these days. This may be true in many places, but not everyone has the benefits of a fast unmetered connection. Reducing download size has an outsized impact for users with slow connections, or those who pay for each gigabyte used.
What does this mean for you?Absolutely nothing! Other than a quicker installation experience, you should see absolutely no changes to the Firefox installation experience.
Of course, edge cases exist and bugs are possible. If you do notice something that you think may be related to this change please file a bug or post on discourse to bring it to our attention.
Get involved!If you’d like to be like Dave, and contribute to Firefox development, take a look at codetribute.mozilla.org. Whether you’re interested in automation and tools, the Firefox frontend, the Javascript engine, or many other things, there’s an opportunity waiting just for you!
Mozilla Addons Blog: Announcing the WebExtensions ML API
Greetings extension developers!
We wanted to highlight this just-published blog post from our AI team where they share some exciting news – we’re shipping a new experimental ML API in Firefox that will allow developers to leverage our AI Runtime to run offline machine learning tasks in their web extensions.
Head on over to Mozilla’s AI blog to learn more. After you’ve had a chance to check it out, we encourage you to share feedback, comments, or questions over on the Mozilla AI Discord (invite link).
Happy coding!
The post Announcing the WebExtensions ML API appeared first on Mozilla Add-ons Community Blog.
Running inference in web extensions

Image generated by DALL*E
We’re shipping a new API in Firefox Nightly that will let you use our Firefox AI runtime to run offline machine learning tasks in your web extension.
Firefox AI RuntimeWe’ve recently shipped a new component inside of Firefox that leverages Transformers.js (a JavaScript equivalent of Hugging Face’s Transformers Python library) and the underlying ONNX runtime engine. This component lets you run any machine learning model that is compatible with Transformers.js in the browser, with no server-side calls beyond the initial download of the models. This means Firefox can run everything on your device and avoid sending your data to third parties.
Web applications can already use Transformers.js in vanilla JavaScript, but running through our platform offers some key benefits:
- The inference runtime is executed in a dedicated, isolated process, for safety and robustness
- Model files are stored using IndexedDB and shared across origins
- Firefox-specific performance improvements are done to accelerate the runtime
This platform shipped in Firefox 133 to provide alt text for images in PDF.js, and will be used in several other places in Firefox 134 and beyond to improve the user experience.
We also want to unblock the community’s ability to experiment with these capabilities. Starting later today, developers will be able to access a new trial “ml” API in Firefox Nightly. This API is basically a thin wrapper around Firefox’s internal API, but with a few additional restrictions for user privacy and security.
There are two major differences between this API and most other WebExtensions APIs: the API is highly experimental and permission to use it must be requested after installation.
This new API is virtually guaranteed to change in the future. To help set developer expectations, the “ml” API is exposed under the “browser.trial” namespace rather than directly on the “browser” global object. Any API exposed on “browser.trial” may not be compatible across major versions of Firefox. Developers should guard against breaking changes using a combination of feature detection and strict_min_version declarations. You can see a more detailed description of how to write extensions with it in our documentation.
Running an inference taskPerforming inference directly in the browser is quite exciting. We expect people will be able to build compelling features using the browser’s data locally.
Like the original Transformers that inspired it, Transformers.js uses “tasks” to abstract away implementation details for performing specific kinds of ML workloads. You can find a description of all tasks that Transformers.js supports in the project’s official documentation.
For our first iteration, Firefox exposes the following tasks:
- text-classification – Assigning a label or class to a given text
- token-classification – Assigning a label to each token in a text
- question-answering – Retrieve the answer to a question from a given text
- fill-mask – Masking some of the words in a sentence and predicting which words should replace those masks
- summarization – Producing a shorter version of a document while preserving its important information.
- translation – Converting text from one language to another
- text2text-generation – converting one text sequence into another text sequence
- text-generation – Producing new text by predicting the next word in a sequence
- zero-shot-classification – Classifying text into classes that are unseen during training
- image-to-text – Output text from a given image
- image-classification – Assigning a label or class to an entire image
- image-segmentation – Divides an image into segments where each pixel is mapped to an object
- zero-shot-image-classification – Classifying images into classes that are unseen during training
- object-detection – Identify objects of certain defined classes within an image
- zero-shot-object-detection – Identify objects of classes that are unseen during training
- document-question-answering – Answering questions on document image
- image-to-image – Transforming a source image to match the characteristics of a target image or a target image domain
- depth-estimation – Predicting the depth of objects present in an image
- feature-extraction – Transforming raw data into numerical features that can be processed while preserving the information in the original dataset
- image-feature-extraction – Transforming raw data into numerical features that can be processed while preserving the information in the original image
For each task, we’ve selected a default model. See the list here EngineProcess.sys.mjs – mozsearch. These curated models are all stored in our Model Hub at https://model-hub.mozilla.org/. A Model Hub is how Hugging Face defines an online storage of models, see The Model Hub. Whether used by Firefox itself or an extension, models are automatically downloaded on the first use and cached.
Below is example below showing how to run a summarizer in your extension with the default model:
async function summarize(text) { await browser.trial.ml.createEngine({taskName: "summarization"}); const result = await browser.trial.ml.runEngine({args: [text]}); return result[0]["summary_text"]; }If you want to use another model, you can use any model published on Hugging Face by Xenova or the Mozilla organization. For now, we’ve restricted downloading models from those two organizations, but we might relax this limitation in the future.
To use an allow-listed model from Hugging Face, you can use an options object to set the “modelHub” option to “huggingface” and the “taskName” option to the appropriate task when creating an engine.
Let’s modify the previous example to use a model that can summarize larger texts:
async function summarize(text) { await browser.trial.ml.createEngine({ taskName: "summarization", modelHub: "huggingface", modelId: "Xenova/long-t5-tglobal-base-16384-book-summary" }); const result = await browser.trial.ml.runEngine({args: [text]}); return result[0]["summary_text"]; }Our PDF.js alt text feature follows the same pattern:
- Gets the image to describe
- Use the “image-to-text” task with the “mozilla/distilvit” model
- Run the inference and return the generated text
This feature is built directly into Firefox, but we’ve also made a web extension example out of it, that you can find in our source code and use as a basis to build your own. See https://searchfox.org/mozilla-central/source/toolkit/components/ml/docs/extensions-api-example. For instance, it includes some code to request the relevant permission, and a model download progress bar.
We’d love to hear from youThis API is our first attempt to enable the community to build on the top of our Firefox AI Runtime. We want to make this API as simple and powerful as possible.
We believe that offering this feature to web extensions developers will help us learn and understand if and how such an API could be developed as a web standard in the future.
We’d love to hear from you and see what you are building with this.
Come and say hi in our dedicated Mozilla AI discord #firefox-ai. Discord invitation: https://discord.gg/Jmmq9mGwy7
Last but not least, we’re doing a deep dive talk at the FOSDEM in the Mozilla room Sunday February 2nd in Brussels. There will be many interesting talks in that room, see: https://fosdem.org/2025/schedule/track/mozilla/
The post Running inference in web extensions appeared first on The Mozilla Blog.
Supercharge your day: Firefox features for peak productivity

Hi, I’m Tapan. As the leader of Firefox’s Search and AI efforts, my mission is to help users find what they are looking for on the web and stay focused on what truly matters. Outside of work, I indulge my geek side by building giant Star Wars Lego sets and sharing weekly leadership insights through my blog, Building Blocks. These hobbies keep me grounded and inspired as I tackle the ever-evolving challenges of the digital world.
I’ve always been fascinated by the internet — its infinite possibilities, endless rabbit holes and the wealth of knowledge just a click away. But staying focused online can feel impossible. I spend my days solving user problems, crafting strategies, and building products that empower people to navigate the web more effectively. Yet, even I am not immune to the pull of distraction. Let me paint you a picture of my daily online life. It’s a scene many of you might recognize: dozens of tabs open, notifications popping up from every corner, and a long to-do list staring at me. In this chaos, I’ve learned that staying focused requires intention and the right tools.
Over the years, I have discovered several Firefox features that are absolute game-changers for staying productive online:
1. Pinned Tabs: Anchor your essentialsPinned Tabs get me to my most essential tabs in one click. I have a few persistent pinned tabs — my email, calendar, and files — and a few “daily” pinned tabs — my “must-dos” of the day tabs. This is my secret weapon for keeping my workspace organized. Pinned Tabs stay put and don’t clutter my tab bar, making it easy to switch between key resources without hunting my tab list.
To pin a tab, right-click it and select “Pin Tab.” Now, your essential tabs will always be at your fingertips.
 2. Search: Use the fast lane
2. Search: Use the fast lane
The “@” shortcut is my productivity superpower, taking me to search results in a flash. By typing “@amazon,” “@bing,” or “@history” followed by your search terms, you can instantly search those platforms or your browsing history without leaving your current page. This saves me time by letting me jump right to search results.
In the next Firefox update, we are making the search term persistent in the address bar so that you can use the address bar to refine your searches for supported sites.

To search supported sites, type “@” in the address bar and pick any engine from the supported list.
3. AI-powered summarization: Cut to the chaseThis is one of my favorite recent additions to Firefox. Our AI summarization feature can distill long articles or documents into concise summaries, helping you grasp the key points without wading through endless text. Recently, I used Firefox’s AI summarization to condense sections of research papers on AI. This helped me quickly grasp the key findings and apply them to our strategy discussions for enhancing Firefox’s AI features. Using AI to help build AI!
To use AI-powered summarization, type “about:preferences#experimental” in the address bar and enable “AI chatbot.” Pick your favorite chatbot and sign in. Select any text on a page you wish to summarize and right-click to pick “Ask <your chatbot>.” We are adding new capabilities to this list with every release.
4. Close Duplicate Tabs: Declutter your workspaceIf you are like me, you’ve probably opened the same webpage multiple times without realizing it. Firefox’s “Close Duplicate Tabs” feature eliminates this problem.
By clicking the tab list icon at the top-right corner of the Firefox window, you can detect and close duplicate tabs, keeping your workspace clean and reducing mental load. This small but mighty tool is for anyone prone to tab overload.
 5. Reader View: Eliminate distractions
5. Reader View: Eliminate distractions
Reader View transforms cluttered web pages into clean, distraction-free layouts. You can focus entirely on the content by stripping away ads, pop-ups, and other distractions. Whether reading an article or researching, this feature keeps your mind on the task.
To enable it, click the Reader View icon in the address bar when viewing a page.
These Firefox features have transformed how I navigate the web, helping me stay focused, productive, and in control of my time online. Whether managing a complex task, diving into research, or just trying to stay on top of your daily tasks, these tools can help you take charge of your browsing experience.
What are your favorite Firefox productivity tips? I would love to hear how you customize Firefox to fit your life.
Let’s make the web work for us!
The post Supercharge your day: Firefox features for peak productivity appeared first on The Mozilla Blog.
Mozilla, EleutherAI publish research on open datasets for LLM training
 Participants of the Dataset Convening in Amsterdam.
Update: Following the 2024 Mozilla AI Dataset Convening, AI builders and researchers publish best practices for creating open datasets for LLM training.
Participants of the Dataset Convening in Amsterdam.
Update: Following the 2024 Mozilla AI Dataset Convening, AI builders and researchers publish best practices for creating open datasets for LLM training.
Training datasets behind large language models (LLMs) often lack transparency, a research paper published by Mozilla and EleutherAI explores how openly licensed datasets that are responsibly curated and governed can make the AI ecosystem more equitable. The study is co-authored with thirty leading scholars and practitioners from prominent open source AI startups, nonprofit AI labs, and civil society organizations who attended the Dataset Convening on open AI datasets in June 2024.
Many AI companies rely on data crawled from the web, frequently without the explicit permission of copyright holders. While some jurisdictions like the EU and Japan permit this under specific conditions, the legal landscape in the United States remains murky. This lack of clarity has led to lawsuits and a trend toward secrecy in dataset practices—stifling transparency, accountability, and limiting innovation to those who can afford it.
For AI to truly benefit society, it must be built on foundations of transparency, fairness, and accountability—starting with the most foundational building block that powers it: data.
The research, “Towards Best Practices for Open Datasets for LLM Training,” outlines possible tiers of openness, normative principles, and technical best practices for sourcing, processing, governing, and releasing open datasets for LLM training, as well as opportunities for policy and technical investments to help the emerging community overcome its challenges.
Building toward a responsible AI future requires collaboration across legal, technical, and policy domains, along with investments in metadata standards, digitization, and fostering a culture of openness.
To help advance the field, the paper compiles best practices for LLM builders, including guidance on Encoding preferences in metadata, Data sourcing, Data Processing, Data Governance/Release, and Terms of Use.
To explore the recommendations check the full paper (also available on arXiv).
We are grateful to our collaborators – 273 Ventures, Ada Lovelace Institute, Alan Turing Institute, Cohere For AI, Common Voice, Creative Commons, Data Nutrition Project, Data Provenance Initiative, First Languages AI Reality (Mila), Gretel, HuggingFace, LLM360, Library Innovation Lab (Harvard), Open Future, Pleias, Spawning, The Distributed AI Research Institute, Together AI, and Ushahidi– for their leadership in this work, as well as Computer Says Maybe for their facilitation support.
We look forward to the conversations it will spark.
Previous post published on July 2, 2024:
Mozilla and EleutherAI brought together experts to discuss a critical question: How do we create openly licensed and open-access LLM training datasets and how do we tackle the challenges faced by their builders?On June 11, on the eve of MozFest House in Amsterdam, Mozilla and EleutherAI convened an exclusive group of 30 leading scholars and practitioners from prominent open-source AI startups, nonprofit AI labs and civil society organizations to discuss emerging practices for a new focus within the open LLM community: creating open-access and openly licensed LLM training datasets.
This work is timely. Although sharing training datasets was once common practice among many AI actors, increased competitive pressures and legal risks have made it almost unheard of nowadays for pre-training datasets to be shared or even described by their developers. However, just as open-source software has made the internet safer and more robust, we at Mozilla and EleutherAI believe open-access data is a public good that can empower developers worldwide to build upon each other’s work. It fosters competition, innovation and transparency, providing clarity around legal standing and an ability to stand up to scrutiny.
Leading AI companies want us to believe that training performant LLMs without copyrighted material is impossible. We refuse to believe this. An emerging ecosystem of open LLM developers have created LLM training datasets —such as Common Corpus, YouTube-Commons, Fine Web, Dolma, Aya, Red Pajama and many more—that could provide blueprints for more transparent and responsible AI progress. We were excited to invite many of them to join us in Amsterdam for a series of discussions about the challenges and opportunities of building an alternative to the current status quo that is open, legally compliant and just.
During the event, we drew on the learnings from assembling “Common Pile” (the soon-to-be-released dataset by EleutherAI composed only of openly licensed and public domain data) which incorporates many learnings from its hugely successful predecessor, “The Pile.” At the event, EleutherAI released a technical briefing and an invitation to public consultation on Common Pile.
 Participants engaged in a discussion at “The Dataset Convening,” hosted by Mozilla and EleutherAI on June 11, 2024 to explore creating open-access and openly licensed LLM training datasets.
Participants engaged in a discussion at “The Dataset Convening,” hosted by Mozilla and EleutherAI on June 11, 2024 to explore creating open-access and openly licensed LLM training datasets.
Our goal with the convening was to bring in the experiences of open dataset builders to develop normative and technical recommendations and best practices around openly licensed and open-access datasets. Below are some highlights of our discussion:
- Openness alone does not guarantee legal compliance or ethical outcomes, we asked which decision points can contribute to datasets being more just and sustainable in terms of public good and data rights.
- We discussed what “good” looks like, what we want to avoid, what is realistic and what is already being implemented in the realm of sourcing, curating, governing and releasing open training datasets.
- Issues such as the cumbersome nature of sourcing public domain and openly licensed data (e.g. extracting text from PDFs), manual verification of metadata, legal status of data across jurisdictions, retractability of consent, preference signaling, reproducibility and data curation and filtering were recurring themes in almost every discussion.
- To enable more builders to develop open datasets and unblock the ecosystem, we need financial sustainability and smart infrastructural investments that can unblock the ecosystem.
- The challenges faced by open datasets today bear a resemblance to those encountered in the early days of open source software (data quality, standardization and sustainability). Back then, it was the common artifacts that united the community and provided some shared understanding and language. We saw the Dataset Convening as an opportunity to start exactly there and create shared reference points that, even if not perfect, will guide us in a common direction.
- The final insight round underscored that we have much to learn from each other: we are still in the early days of solving this immense challenge, and this nascent community needs to collaborate and think in radical and bold ways.
 Participants at the Mozilla and EleutherAI event collaborating on best practices for creating open-access and openly licensed LLM training datasets.
Participants at the Mozilla and EleutherAI event collaborating on best practices for creating open-access and openly licensed LLM training datasets.
We are immensely grateful to the participants in the Dataset Convening (including some remote contributors):
- Stefan Baack — Researcher and Data Analyst, Insights, Mozilla
- Mitchell Baker — Chairwoman, Mozilla Foundation
- Ayah Bdeir — Senior Advisor, Mozilla
- Julie Belião — Senior Director of Product Innovation, Mozilla.ai
- Jillian Bommarito — Chief Risk Officer, 273 Ventures
- Kasia Chmielinski — Project Lead, Data Nutrition Project
- Jennifer Ding — Senior Researcher, Alan Turing Institute
- Alix Dunn — CEO, Computer Says Maybe
- Marzieh Fadaee — Senior Research Scientist, Cohere For AI
- Maximilian Gahntz — AI Policy Lead, Mozilla
- Paul Keller — Director of Policy and Co-Founder, Open Future
- Hynek Kydlíček — Machine Learning Engineer, HuggingFace
- Pierre-Carl Langlais — Co-Founder, Pleias
- Greg Leppert — Director of Product and Research, the Library Innovation Lab, Harvard
- EM Lewis-Jong — Director, Common Voice, Mozilla
- Shayne Longpre — Project Lead, Data Provenance Initiative
- Angela Lungati — Executive Director, Ushahidi
- Sebastian Majstorovic — Open Data Specialist, EleutherAI
- Cullen Miller — Vice President of Policy, Spawning
- Victor Miller — Senior Product Manager, LLM360
- Kasia Odrozek — Director, Insights, Mozilla
- Guilherme Penedo — Machine Learning Research Engineer, HuggingFace
- Neha Ravella — Research Project Manager, Insights Mozilla
- Michael Running Wolf — Co-Founder and Lead Architect, First Languages AI Reality, Mila
- Max Ryabinin — Distinguished Research Scientist, Together AI
- Kat Siminyu — Researcher, The Distributed AI Research Institute
- Aviya Skowron — Head of Policy and Ethics, EleutherAI
- Andrew Strait — Associate Director, Ada Lovelace Institute
- Mark Surman — President, Mozilla Foundation
- Anna Tumadóttir — CEO, Creative Commons
- Marteen Van Segbroeck — Head of Applied Science, Gretel
- Leandro von Werra — Chief Loss Officer, HuggingFace
- Maurice Weber — AI Researcher, Together AI
- Lee White — Senior Full Stack Developer, Ushahidi
- Thomas Wolf — Chief Science Officer and Co-Founder, HuggingFace
In the coming weeks, we will be working with the participants to develop common artifacts that will be released to the community, along with an accompanying paper. These resources will help researchers and practitioners navigate the definitional and executional complexities of advancing open-access and openly licensed datasets and strengthen the sense of community.
The event was part of the Mozilla Convening Series, where we bring together leading innovators in open source AI to tackle thorny issues and help move the community and movement forward. Our first convening was the Columbia Convening where we invited 40 leading scholars and practitioners to develop a framework for defining what openness means in AI. We are committed to continuing the efforts to support communities invested in openness around AI and look forward to helping grow and strengthen this movement.
The post Mozilla, EleutherAI publish research on open datasets for LLM training appeared first on The Mozilla Blog.
Streamline your schoolwork with Firefox’s PDF editor
As a student pursuing a master’s degree, I’ve spent too much time searching for PDF editors to fill out forms, take notes and complete projects. I discovered Firefox’s built-in PDF editor while interning at Mozilla as a corporate communications intern. No more giving out my email address or downloading dubious software, which often risks data. The built-in PDF tool on Firefox is a secure, efficient solution that saves me time. Here’s how it has made my academic life easier.
Fill out applications and forms effortlesslyRemember those days when you had to print a form, fill it out and then scan it back into your computer? I know, tedious. With Firefox’s PDF editor, you can fill in forms online directly from your browser. Just open the PDF in Firefox on your smartphone or computer, click the “text” button, and you’re all set to type away. It’s a gamechanger for all those scholarship applications and administrative forms, or even adult-life documents we consistently have to fill.
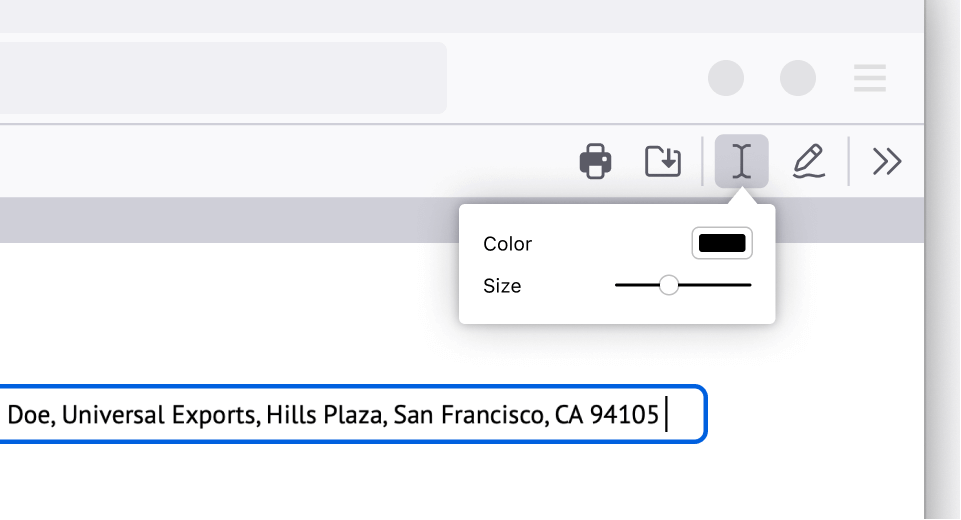 Highlight and annotate lecture slides for efficient note-taking
Highlight and annotate lecture slides for efficient note-taking
I used to print my professors’ lecture slides and study materials just to add notes. Now, I keep my annotations within the browser – highlighting key points and adding notes. You can even choose your text size and color. This capability not only enhances my note-taking, it saves some trees too. No more losing 50-page printed slides around campus.
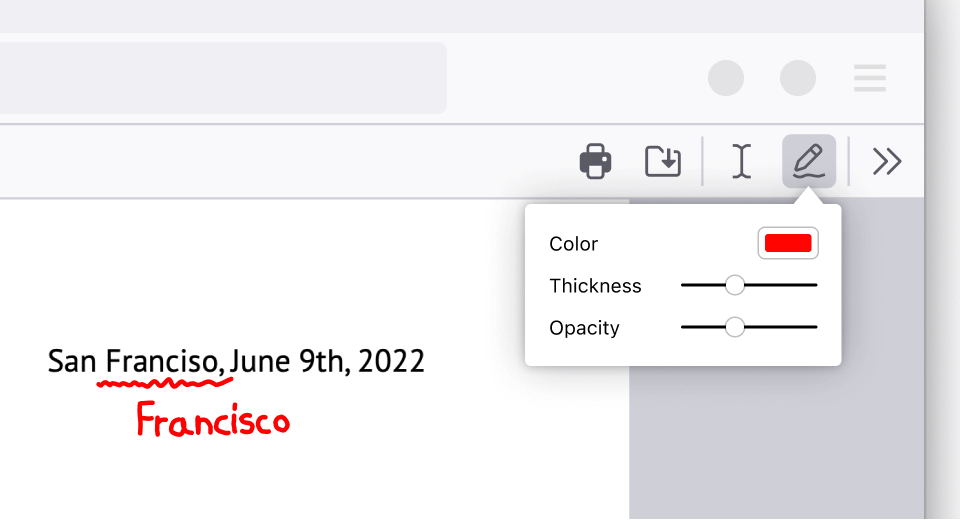
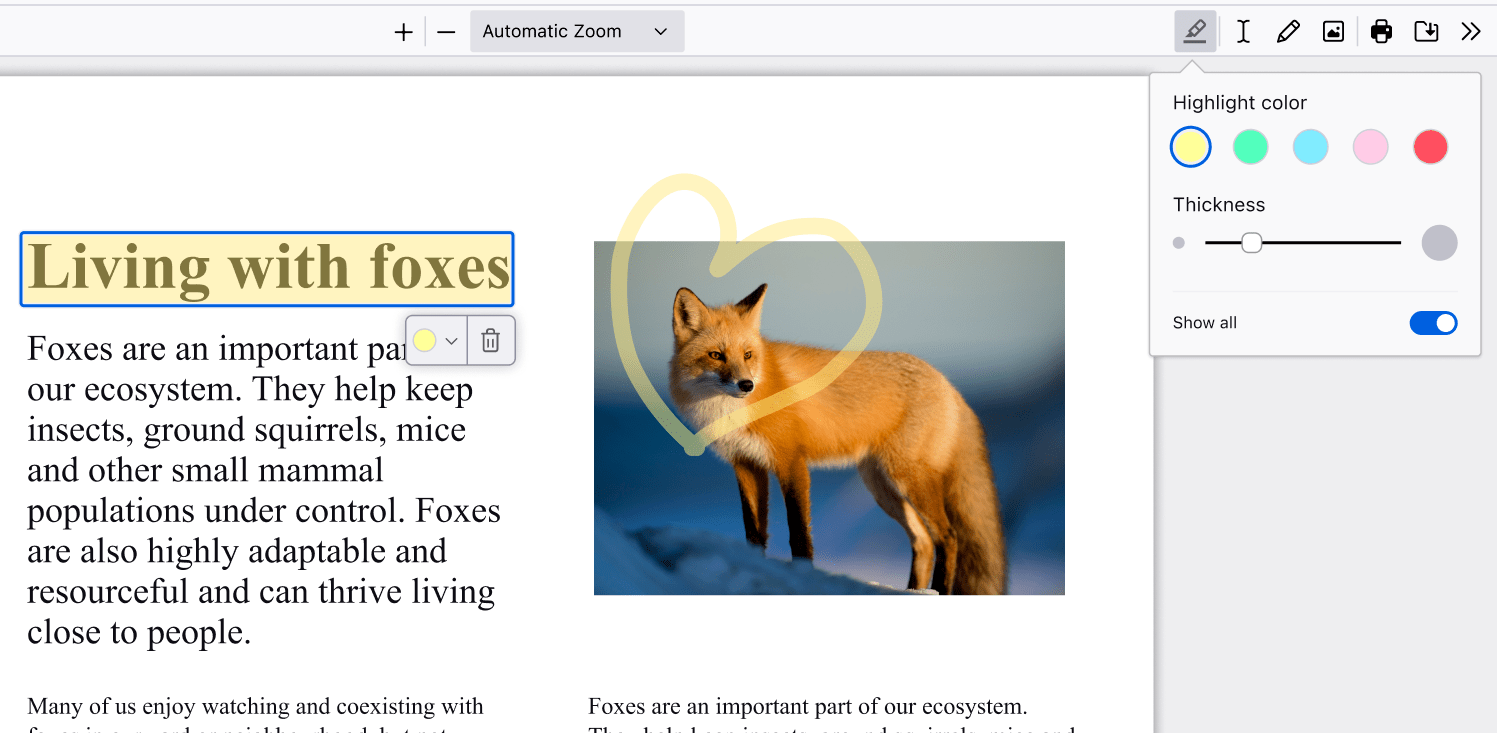 Sign documents electronically without hassle
Sign documents electronically without hassle
Signing a PDF document was the single biggest dread I had as a millennial, a simple task made difficult. I used to have to search “free PDF editor” online, giving my personal information to make an account in order to use free software. Firefox makes it simple. Here’s how: Click the draw icon, select your preferred color and thickness, and draw directly on the document. Signing documents electronically finally feels like a 21st century achievement.
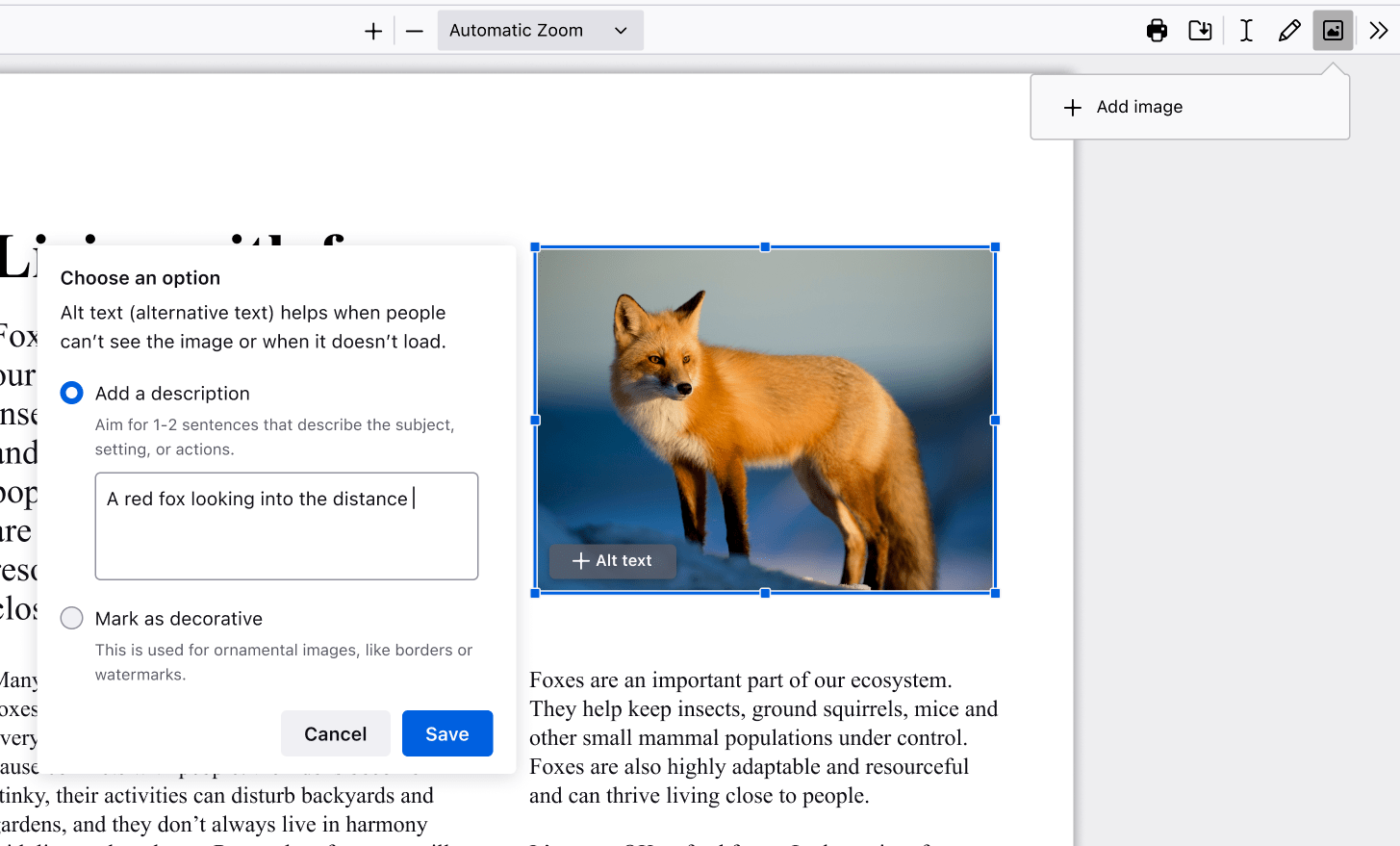
 Easily insert and customize images in your PDFs
Easily insert and customize images in your PDFs
Sometimes, adding an image to your PDF is necessary, whether it’s a graph for a report or a picture for a project. Firefox lets you upload and adjust images right within the PDF. You can even add alternative text or alt-text to make your documents more accessible, ensuring everyone in your group can understand your work.
There are endless ways to make Firefox your own, however you choose to navigate the internet. We want to know how you customize Firefox. Let us know and tag us on X or Instagram at @Firefox.
The post Streamline your schoolwork with Firefox’s PDF editor appeared first on The Mozilla Blog.
Pagina's
- 1
- 2
- 3
- 4
- volgende ›
- laatste »