
Mozilla Thunderbird: Thunderbird Monthly Development Digest: September 2024

Hello Thunderbird Community! I’m Toby Pilling, a new team member and I’ve spent the last couple of months getting up to speed, and have really enjoyed meeting the team and members of the community virtually, and some in person! September is now over (and so is the summer for many in our team), and we’re excited to share the latest adventures underway in the Thunderbird world. If you missed our previous update, go ahead and catch up! Here’s a quick summary of what’s been happening across the different teams:
ExchangeProgress continues on implementing move/copy operations, with the ongoing re-architecture aimed at making the protocol ecosystem more generic. Work has also started on error handling, protocol logging and a testing framework. A Rust starter pack has been provided to facilitate on-boarding of new team members with automated type generation as the first step in reducing the friction.
Account HubDevelopment of a refreshed account hub is moving forward, with design work complete and a critical path broken down into sprints. Project milestones and tasks have been established with additional members joining the development team in October. Meta bug & progress tracking.
Global Database & Conversation ViewThe team is focused on breaking down the work into smaller tasks and setting feature deliverables. Initial work on integrating a unique IMAP ID is being rolled out, while the conversation view feature is being fast-tracked by a focused team, allowing core refactoring to continue in parallel.
In-App NotificationThis initiative will provide a mechanism to notify users of important security updates and feature releases “in-app”, in a subtle and unobtrusive manner, and has advanced at break-neck speed with impressive collaboration across each discipline. Despite some last-minute scope creep, the team has moved swiftly into the testing phase with an October release in mind. Meta Bug & progress tracking.
Source Docs Clean-upWork continues on source documentation clean-up, with support from the release management team who had to reshape some of our documentation toolset. The completion of this project will move much of the developer documentation closer to the actual code which will make things much easier to maintain moving forwards. Stay tuned for updates to this in the coming week and follow progress here.
Account Cross-Device ImportAs the launch date for Thunderbird for Android gets closer, we’re preparing a feature in the desktop client which will provide a simple and secure account transfer mechanism, so that account settings don’t have to be re-entered for new users of the Android client. A functional prototype was delivered quickly. Now that design work is complete, the project entered the 2 final sprints this week. Keep track here.
Battling OAuth ChangesAs both Microsoft and Google update their OAuth support and URLs, the team has been working hard to minimize the effect of these changes on our users. Extended logging in Daily will allow for better monitoring and issue resolution as these updates roll out.
New Features Landing SoonSeveral requested features are expected to debut this month or very soon:
- Horizontal scrolling for emails in table view as a user preference.
- Calendar support for ICS import including a Comments field.
- Certificate viewer to support validation.
- Encrypted draft messages even when no recipients are specified.
- UI enhancements and bug fixes for the calendar, RSS, and mail modules.
As usual, if you want to see things as they land you can check the pushlog and try running daily. This would be immensely helpful for catching bugs early.
See ya next month.
Toby Pilling
Sr. Manager, Desktop Engineering
The post Thunderbird Monthly Development Digest: September 2024 appeared first on The Thunderbird Blog.
The Servo Blog: This month in Servo: Android nightlies, right-to-left, WebGPU, and more!
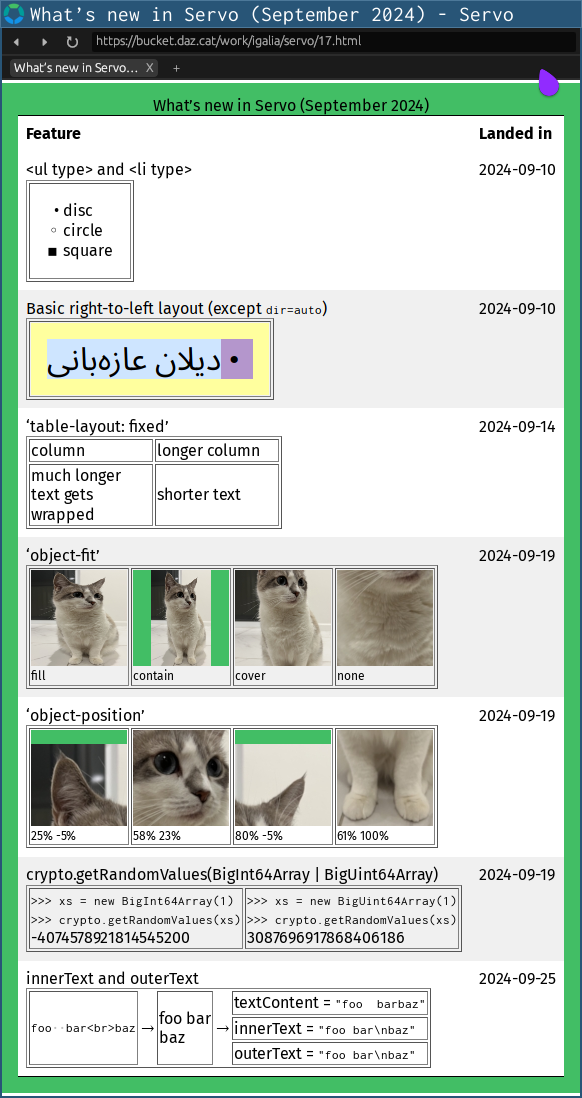
Servo has had several new features land in our nightly builds over the last month:
- as of 2024-09-10, we now support <ul type> and <ul compact> (@simonwuelker, #33303)
- as of 2024-09-10, we now support console.timeLog() (@simonwuelker, #33377)
- as of 2024-09-10, we now support the encodeInto() method on TextEncoder (@webbeef, @mrobinson, #33360)
- as of 2024-09-10, we now support <link rel=prefetch> (@simonwuelker, #33345)
- as of 2024-09-12, we now support right-to-left languages, except for floats (@mrobinson, @atbrakhi, #33375)
- as of 2024-09-14, we now support ‘table-layout: fixed’ (@Loirooriol, @mrobinson, #33384, #33442)
- as of 2024-09-17, we now support the ‘reset’ event on XRReferenceSpace properties (@msub2, #33460)
- as of 2024-09-19, we now support the ‘object-fit’ and ‘object-position’ properties (@mrobinson, @Loirooriol, #33479)
- as of 2024-09-19, Crypto.getRandomValues() can now take BigInt64Array or BigUint64Array (@msub2, #33485)
- as of 2024-09-25, we now support ‘innerText’ and ‘outerText’ on HTMLElement (@Melchizedek6809, @shanehandley, #33312)
Servo’s flexbox support continues to mature, with support for ‘align-self: normal’ (@Loirooriol, #33314), plus corrections to cross-axis percent units in descendants (@Loirooriol, @mrobinson, #33242), automatic minimum sizes (@Loirooriol, @mrobinson, #33248, #33256), replaced flex items (@Loirooriol, @mrobinson, #33263), baseline alignment (@mrobinson, @Loirooriol, #33347), and absolute descendants (@mrobinson, @Loirooriol, #33346).
Our table layout has improved, with support for width and height presentational attributes (@Loirooriol, @mrobinson, #33405, #33425), as well as better handling of ‘border-collapse’ (@Loirooriol, #33452) and extra <col> and <colgroup> columns (@Loirooriol, #33451).
We’ve also started working on the intrinsic sizing keywords ‘min-content’, ‘max-content’, ‘fit-content’, and ‘stretch’ (@Loirooriol, @mrobinson, #33492). Before we can support them, though, we needed to land patches to calculate intrinsic sizes, including for percent units (@Loirooriol, @mrobinson, #33204), aspect ratios of replaced elements (@Loirooriol, #33240), column flex containers (@Loirooriol, #33299), and ‘white-space’ (@Loirooriol, #33343).
We’ve also worked on our WebGPU support, with support for pipeline-overridable constants (@sagudev, #33291), and major rework to GPUBuffer (@sagudev, #33154) and our canvas presentation (@sagudev, #33387). As a result, GPUCanvasContext now properly supports (re)configuration and resize on GPUCanvasContext (@sagudev, #33521), presentation is now faster, and both are now more conformant with the spec.
Performance and reliabilityServo now sends font data over shared memory (@mrobinson, @mukilan, #33530), saving a huge amount of time over sending font data over IPC channels.
We now debounce resize events for faster window resizing (@simonwuelker, #33297), limit document title updates (@simonwuelker, #33287), and use DirectWrite kerning info for faster text shaping on Windows (@crbrz, #33123).
Servo has a new kind of experimental profiling support that can send profiling data to Perfetto (on all platforms) and HiTrace (on OpenHarmony) via tracing (@atbrakhi, @delan, #33188, #33301, #33324), and we’ve instrumented Servo with this in several places (@atbrakhi, @delan, #33189, #33417, #33436). This is in addition to Servo’s existing HTML-trace-based profiling support.
We’ve also added a new profiling Cargo profile that builds Servo with the recommended settings for profiling (@delan, #33432). For more details on building Servo for profiling, benchmarking, and other perf-related use cases, check out our updated Building Servo chapter (@delan, book#22).
Build timesThe first patch towards splitting up our massive script crate has landed (@sagudev, #33169), over ten years since that issue was first opened.
script is the heart of the Servo rendering engine — it contains the HTML event loop plus all of our DOM APIs and their bindings to SpiderMonkey, and the script thread drives the page lifecycle from parsing to style to layout. script is also a monolith, with over 170 000 lines of hand-written Rust plus another 520 000 lines of generated Rust, and it has long dominated Servo’s build times to the point of being unwieldy, so it’s very exciting to see that we may be able to change this.
Contributors to Servo can now enjoy faster self-hosted CI runners for our Linux builds (@delan, @mrobinson, #33321, #33389), cutting a typical Linux-only build from over half an hour to under 8 minutes, and a typical T-full try job from over an hour to under 42 minutes.
We’ve now started exploring self-hosted macOS runners (@delan, ci-runners#3), and in the meantime we’ve landed several fixes for self-hosted build failures (@delan, @sagudev, #33283, #33308, #33315, #33373, #33471, #33596).
 Beyond the engine
Beyond the engine
You can now download the Servo browser for Android on servo.org (@mukilan, #33435)! servoshell now supports gamepads by default (@msub2, #33466), builds for OpenHarmony (@mukilan, #33295), and has better navigation on Android (@msub2, #33294).
Tabbed browsing on desktop platforms has become a lot more polished, with visible close and new tab buttons (@Melchizedek6809, #33244), key bindings for switching tabs (@Melchizedek6809, #33319), as well as better handling of empty tab titles (@Melchizedek6809, @mrobinson, #33354, #33391) and the location bar (@webbeef, #33316).
We’ve also fixed several HiDPI bugs in servoshell (@mukilan, #33529), as well as keyboard input and scrolling on Windows (@crbrz, @jdm, #33225, #33252).
DonationsThanks again for your generous support! We are now receiving 4147 USD/month (+34.7% over July) in recurring donations. This includes donations from 12 people on LFX, but we will stop accepting donations there soon — please move your recurring donations to GitHub or Open Collective.
Servo is also on thanks.dev, and already eleven GitHub users that depend on Servo are sponsoring us there. If you use Servo libraries like url, html5ever, selectors, or cssparser, signing up for thanks.dev could be a good way for you (or your employer) to give back to the community.
4147 USD/month 10000With this money, we’ve been able to pay for our web hosting and self-hosted CI runners for Windows and Linux builds, and when the time comes, we’ll be able to afford macOS runners, perf bots, and maybe even an Outreachy intern or two! As always, use of these funds will be decided transparently in the Technical Steering Committee. For more details, head to our Sponsorship page.
Don Marti: why I’m turning off Firefox ad tracking: the PPA paradox
Previously: turn off advertising features in Firefox
I am turning off the controversial Privacy-preserving attribution (PPA) advertising tracking feature in Firefox, even though, according to the documentation, there are some good things about PPA compared to cookies:
You can’t be identified individually as the same person who saw an ad and then bought something
A site can’t tell if you have PPA on or off
Those are both interesting and desirable properties, and the PPA system, if implemented correctly and run honestly, does not look like a problem on its own. So why are people creeped out by it? That creeped-out feeling is not coming from privacy math ignorance, it’s people’s inner behavioral economists warning about an information imbalance. Just like people who grow up playing ball can catch a ball without consciously doing calculus, people who grow up in market economies get a pretty good sense of markets and information, which manifests as a sense of being creeped out when something about a market design doesn’t seem right.
The problem is not the design of PPA on its own, it’s that PPA is being proposed as something to run on the real Web, a place where you can find both the best legit ad-supported content and the most complicated scams. And that creates a PPA paradox: this privacy-preserving attribution feature, if it catches on, will tend to increase the amount of surveillance. PPA doesn’t have all of the problems of privacy-enhancing technologies in web browsers, but this is a big one.
Briefly, the way that PPA is designed to work is that sites that run ads will run JavaScript to request that the browser store impression events to keep a record of the ad you saw, and then a site where you buy stuff can record a conversion and then get a report to find out which sites the people who bought stuff had seen ads on. The browser doesn’t directly share the impression events with the site where you buy stuff. It generates an encrypted message that might or might not include impressions, then the site passes those encrypted messages to secure services to do math on them and create an aggregated report. The report doesn’t make it possible to match any individual ad impression to any individual sale.
So, as a web entrepreneur willing to bend the rules, how would you win PPA? You could make a site where people pay attention to the ads, and hope that gets them to buy stuff, so you get more ad money that way. The problem with that is that legit ad-supported content and legit, effective advertising are both hard. Not only do you need to make a good site, the advertisers who run their ads on it need to make effective ads in order for you to win this way. An easier way to win the PPA game is to run a crappy site and then (1) figure out who’s about to buy, (2) trick those people into visiting your crappy site, and (3) tell the browser to store an impression before the sale you predicted, so that your crappy site gets credit for making the sale. And steps 1 and 2 work better and better the more surveillance you can do, including tracking people between web and non-web activity, smart TV mics, native mobile SDKs, server-to-server CAPIs, malware, use your imagination.
(Update 14 Oct 2024) PPA has an antitrust problem, too. In a market where the average user has their activity passed to Meta by thousands of companies, Meta has a large advantage when training a machine learning system to steal conversions by placing an ad in front of someone who would be likely to buy anyway. With PPA, a large surveillance company would not have to deliberately tell anyone to do fraud, or write code to do fraud. Instead, ML systems designed to win PPA would learn to do fraud, since if you have the surveillance data anyway, fraud is the quickest, easiest way to get money. (Like I said, legit conversions are hard.) And unlike what happened in legacy fraud cases like Uber v. Fetch, with PPA enough data is deliberately obfuscated to make the fraud impossible to track down. Only a few large companies have the combination of ML and large inflows of user data to make this kind of invisible, deniable fraud possible, so PPA looks like a tool for problematic concentration in the Internet and advertising businesses.
Of course, attribution stealing schemes are a thing with conventional cookie and mobile app tracking, too. And they have been for quite a while. But conventional tracking generally produces enough extra info to make it possible to do more interesting attribution systems that enable marketers to figure out when legit and not-so-legit conversions are happening. If you read Mobile Dev Memo by Eric Seufert and other high-end marketing sites, there is a lot of material about more sophisticated atribution models than what’s possible with PPA. Marketers have a constant set of stats problems to solve to figure out which of the ads are going to influence people in the direction of buying stuff, and which ad money is being wasted because it gets spent on claiming credit for selling a thing that customers were going to buy anyway. PPA doesn’t provide the info needed to get good answers for those stats problems—so what works like a privacy feature on its own would drive the development and deployment of more privacy risks. I’m turning it off, and I hope that enough people will join me to keep PPA from catching on.
More: or we could just not
RelatedCampaigners claim ‘Privacy Preserving Attribution’ in Firefox does the opposite (more coverage of the EU complaint)
Google’s revised ad targeting plan triggers fresh competition concerns in UK
Protecting Your Privacy While Eroding Your Democracy: Apple’s and Mozilla’s PPAs (Privacy Preserving Ad Attribution) Considered Harmful by Asif Youssuff Unfortunately, after studying each proposal, I predict they will inadvertently lend themselves to further incentivize the publication and spread of low-quality information (including misinformation), polluting the information landscape and threatening democracies worldwide.
the colored pencil test for web features A web browser is the agent of the user, and should act in the user’s interest, which means doing what the user would do for themselves if they had time.
Mozilla Thunderbird: State Of The Bird: Thunderbird Annual Report 2023-2024

We’ve just released Thunderbird version 128, codenamed “Nebula”, our yearly stable release. So with that big milestone done, I wanted to take a moment and tell our community about the state of Thunderbird. In the past I’ve done a recap focused solely on the project’s financials, which is interesting – but doesn’t capture all of the great work that the project has accomplished. So, this time, I’m going to try something different. I give you the State of the Bird: Thunderbird Annual Report 2023-2024.
Before we jump into it, on behalf of the Thunderbird Team and Council, I wanted to extend our deepest gratitude to the hundreds of thousands of people who generously provided financial support to Thunderbird this past year. Additionally, Thunderbird would like to thank the many volunteers who contributed their time to our many efforts. It is not an exaggeration to say that this product would not exist without them. All of our contributors are the lifeblood of Thunderbird. They are the beacons shining brightly to remind us of the transformative power of open source, and the influence of the community that stands alongside it. Thank you for not just being on this journey with us, but for making the journey possible.
Supernova & NebulaThunderbird Supernova 115 blazed into existence on July 11, 2023. This Extended Support Release (ESR) not only introduced cool code names for releases, but also helped bring Thunderbird a modern look and experience that matched the expectation of users in 2023. In addition to shedding our outdated image, we also started tackling something which prevented a brisk development pace and steady introduction of new features: two decades of technical debt.
After three years of slow decline in Daily Active Users (DAUs), the Supernova release started a noticeable upward trend, which reaffirms that the changes we made in this release are putting us on the right track. What our users were responding to wasn’t just visual, however. As we’ve noted many times before – Supernova was also a very large architectural overhaul that saw the cleanup of decades of technical debt for the mail front-end. Supernova delivered a revamped, customizable mail experience that also gave us a solid foundation to build the future on.
Fast forwarding to Nebula, released on July 11, 2024, we built upon many of the pillars that made Supernova a success. We improved the look and feel, usability, customization and speed of the mail experience in truly substantial ways. Additionally, many of the investments in improving the Thunderbird codebase began to pay dividends, allowing us to roll in preliminary Exchange support and use native OS notifications.
All of the work that has happened with Supernova and Nebula is an effort to make Thunderbird a first-class email and productivity tool in its own right. We’ve spent years paying down technical debt so that we could focus more on the features and improvements that bring value to our users. This past year we got to leverage all that hard work to create a truly great Thunderbird experience.
K-9 Mail & Thunderbird For AndroidIn response to the enormous demand for Thunderbird on a phone, we’ve worked hard to lay a solid foundation for our Android release. The effort to turn K-9 Mail into something we can confidently call a great Thunderbird experience on-the-go is coming along nicely.
In April of 2023, we released K-9 6.600 with a message view redesign that brought K-9 and Thunderbird more in line. This release also had a more polished UI, among other fixes, improvements, and changes. Additionally, it integrated our new design system with reusable components that will allow quicker responses to future design changes in Android.
The 6.7xx Beta series, developed throughout 2023, primarily focused on improving account setup. The main reason for this change is to enable seamless email account setup. This also started the transition of K-9’s UI from traditional Android XML layouts to using the more modern and now recommended Jetpack Compose UI toolkit, and the adoption of Atomic Design principles for a cohesive, intuitive design. The 6.710 Beta release in August was the first to include the new account setup for more widespread testing. Introducing new account setup code and removing some of the old code was a step in the right direction.
In other significant events of 2023, we hired Wolf Montwé as a senior software engineer, doubling the K-9 Mail team at MZLA! We also conducted a security audit with 7ASecurity and OSTIF. No critical issues were found, and many non-critical issues were fixed. We began experimenting with Material 3 and based on positive results, decided to switch to Material 3 before renaming the app. Encouraged by our community contributors, we moved to Weblate for localization. Weblate is better integrated into K-9 and is open source. Some of our time was also spent on necessary maintenance to ensure the app works properly on the latest Android versions.
So far this year, we’ve shipped the account setup improvements to everyone and continued work on Material 3 and polishing the app in preparation for its transition to “Thunderbird for Android.” You can look at individual release details in our GitHub repository and track the progress we’ve made there. Suffice to say, the work on creating an amazing Android experience has been significant – and we look forward to sharing the first true Thunderbird release on Android in the next few months.
Services and InfrastructureIn 2023 we began working in earnest on delivering additional value to Thunderbird users through a suite of web services. The reasoning? There are some features that would add significant value to our users that we simply can’t do in the Thunderbird clients alone. We can, however, create amazing, open source, privacy-respecting services that enhance the Thunderbird experience while aligning with our values – and that’s what we’ve been doing.
The services that we’ve focused on are: Appointment, a calendar scheduling tool; Send, an encrypted large-file transfer service; and Thunderbird Sync, which will allow users to sync their Thunderbird settings between devices (both desktop and Android).
Thunderbird Appointment enables you to plan less and do more. You can add your calendars to the service, outline your weekly availability and then send links that allow others to grab time on your schedule. No more long back-and-forth email threads to find a time to meet, just send a link. We’ve just opened up beta testing for the service and look forward to hearing from early users what features our users would like to see. For more information on Thunderbird Appointment, and if you’d like to sign up to be a beta tester, check out our Thunderbird Appointment blog post. If you want to look at the code, check out the repository for the project on GitHub.
The Thunderbird team was very sad when Firefox Send was shut down. Firefox Send made it possible to send large files easily, maybe easier than any other tool on the Internet. So we’re reviving it, but not without some nice improvements. Thunderbird Send will not only allow you to send large files easily, but our version also encrypts them. All files that go through Send are encrypted, so even we can’t see what you share on the service. This privacy focus was important in building this tool because it’s one of our core values, spelled out in the Mozilla Manifesto (principle 4): “Individuals’ security and privacy on the internet are fundamental and must not be treated as optional.”
Finally, after many requests for this feature, I’m happy to share that we are working hard to make Thunderbird Sync available to everyone. Thunderbird Sync will allow you to sync your account and application settings between Thunderbird clients, saving time at setup and headaches when you use Thunderbird on multiple devices. We look forward to sharing more on this front in the near future.
2023 Financial PictureAll of the above work was made possible because of our passionate community of Thunderbird users. 2023 was a year of significant investment into our team and our infrastructure, designed to ensure the continued long-term stability and sustainability of Thunderbird. As previously mentioned these investments would not have been possible without the remarkable generosity of our financial contributors.
Contribution RevenueTotal financial contributions in 2023 reached $8.6M, reflecting a 34.5% increase over 2022. More than 515,000 transactions from over 300,000 individual contributors generated this financial support (26% of the transactions were recurring monthly contributions).
In addition to that incredible total, what stands out is that the majority of our contributions were modest. The average contribution amount was $16.90, and the median amount was $11.12.
We are often asked if we have “super givers” and the refreshing answer is “no, we simply have a super community.” To underscore this, consider that 61% of giving was $20 or less, and 95% of the transactions were $35 or less. The number of transactions $1000 and above accounted for only 56 transactions; that’s effectively 0.0007% of all contribution transactions.
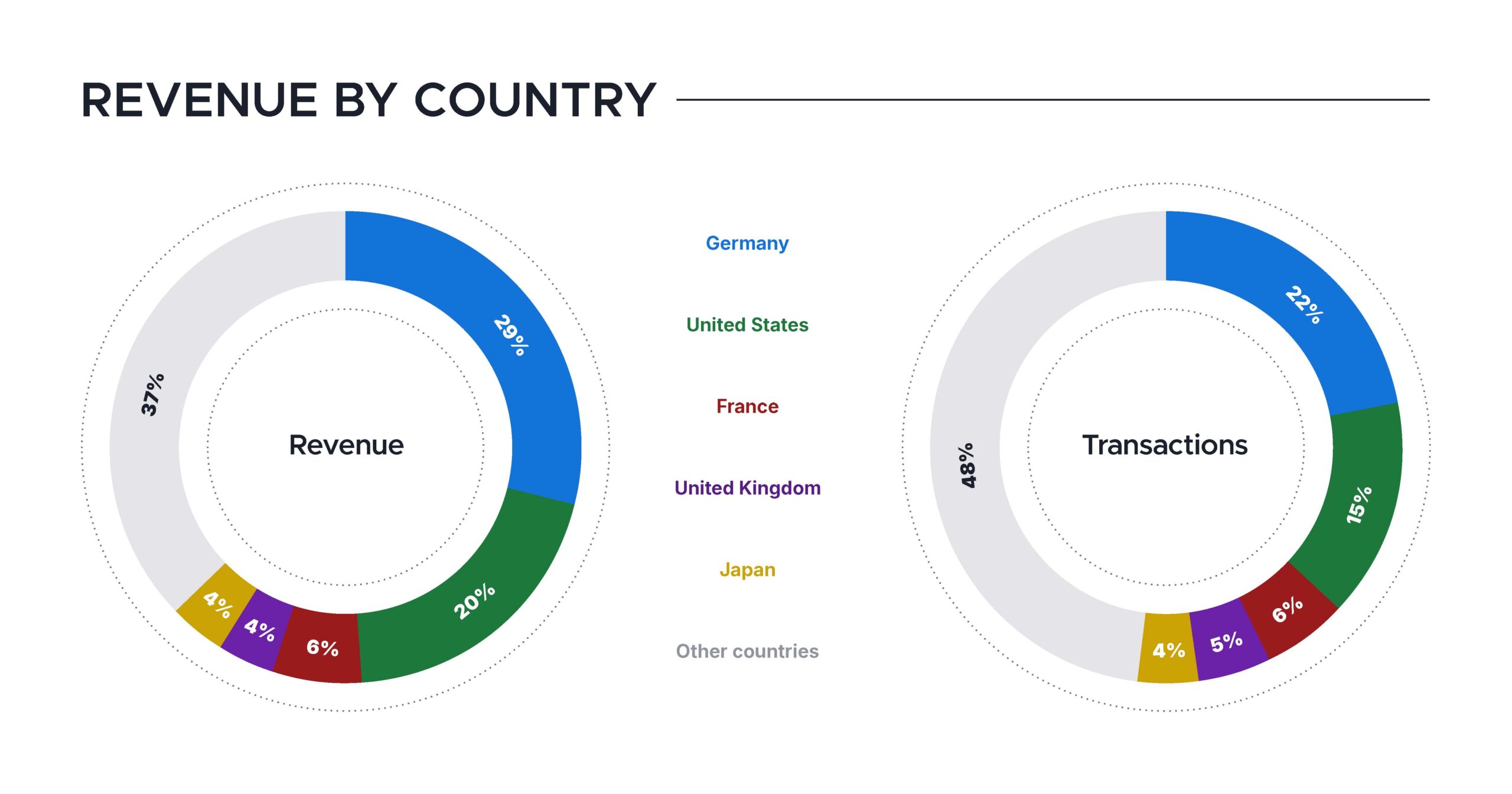
And this super community helping us sustain and improve Thunderbird is very much a global one, with contributions pouring in from more than 200 countries! The top five giving countries — Germany, the United States, France, the United Kingdom, and Japan — accounted for 63% of our contribution revenue and 50% of transactions. We believe this global support is a testament to the universal value of Thunderbird and the core values the project stands for.
ExpensesNow, let’s talk about how we’re using these funds to keep Thunderbird thriving well into the future.
As with most organizations, employee-related expenses are the largest expense category. The second highest category for us are all the costs associated with distributing Thunderbird to tens of millions of users and the operations that help make that happen. You can see our spending across all categories below:

The Importance of Supporting Thunderbird
When I started at Thunderbird (in 2017), we weren’t on a sustainable path. The cost of building, maintaining and distributing Thunderbird to tens of millions of people was too great when compared against the financial contributions we had coming in. Fast forward to 2023 and we’re able to not only deliver Thunderbird to our users without worrying about keeping the lights on, but we are able to fix bugs, build new features and invest in new platforms (Android). It’s important for Thunderbird to exist because it’s not just another app, but one built upon real values.
Our values are:
- We believe in privacy. We don’t collect your data or spy on you, what you do in Thunderbird is your business, not ours.
- We believe in digital wellbeing. Thunderbird has no dark patterns, we don’t want you doomscrolling your email. Apps should help, not hurt, you. We want Thunderbird to help you be productive.
- We believe in open standards. Email works because it is based on open standards. Large providers have undermined these standards to lock users into their platforms. We support and develop the standards to everyone’s benefit.
If you share these values, we ask that you consider supporting Thunderbird. The tech you use doesn’t have to be built upon compromises. Giving to Thunderbird allows us to create good software that is good for you (and the world). Consider giving to support Thunderbird today.
2023 Community SnapshotAs we’ve noted so many times in the previous paragraphs, it’s because of Thunderbird’s open source community that we exist at all. In order to better engage with and acknowledge everyone participating in our projects, this past year we set up a Bitergia instance, which is now public. Bitergia has allowed us to better measure participation in the community and find where we are doing well and improving, and areas where there is room for improvement. We’ve pulled out some interesting metrics below.
For reference, Github and Bugzilla measure developer contributions. TopicBox measures activity across our many mailing lists. Pontoon measures the activity from volunteers who help us translate and localize Thunderbird. SUMO measures the impact of Thunderbird’s support volunteers who engage with our users and respond to their varied support questions.
Contributor & Community Growth Thank You
Thank You
In conclusion, we’d simply like to thank this amazing community of Thunderbird supporters who give of their time and resources to create something great. 2023 and 2024 have been years of extraordinary improvement for Thunderbird and the future looks bright. We’re humbled and pleased that so many of you share our values of privacy, digital wellbeing and open standards. We’re committed to continuing to provide Thunderbird for free to everyone, everywhere – thanks to you!
The post State Of The Bird: Thunderbird Annual Report 2023-2024 appeared first on The Thunderbird Blog.
Support.Mozilla.Org: Introducing Andrea Murphy
Hi folks,
Super excited to share with you all. Andrea Murphy is joining our team as a Customer Experience Community Program Manager, covering for Konstantina while she’s out on maternity leave. Here’s a short intro from Andrea:
Greetings everyone! I’m thrilled to join the team as Customer Experience Community Program Manager. I work on developing tools, programs and experiences that support, inspire and empower our extraordinary network of volunteers. I’m from Rochester, NY and when I’m not at the office, I’m chasing waterfalls around our beautiful state parks, playing pinball or planning road trips with carefully curated playlists that include fun facts about all of my favorite artists. I’m a pop culture enthusiast, and very good at pub trivia. Add me to your team!
You’ll get a chance to meet Andrea in today’s community call. In the meantime, please join me to welcome Andrea into our community. (:
Firefox Developer Experience: Firefox WebDriver Newsletter 131
WebDriver is a remote control interface that enables introspection and control of user agents. As such it can help developers to verify that their websites are working and performing well with all major browsers. The protocol is standardized by the W3C and consists of two separate specifications: WebDriver classic (HTTP) and the new WebDriver BiDi (Bi-Directional).
This newsletter gives an overview of the work we’ve done as part of the Firefox 131 release cycle.
ContributionsFirefox – including our WebDriver implementation – is developed as an open source project, and everyone is welcome to contribute. If you ever wanted to contribute to an open source project used by millions of users, or are interested in some experience in software development, jump in.
We are always grateful to receive external contributions, here are the ones which made it in Firefox 131:
- Dan (temidayoazeez032) added a base RootBiDiModule class and an emitEventForBrowsingContext method in it to make it easier to share the code between the WebDriver BiDi root modules.
WebDriver code is written in JavaScript, Python, and Rust so any web developer can contribute! Read how to setup the work environment and check the list of mentored issues for Marionette.
General Bug fixes- For both WebDriver Classic and BiDi the "keyUp” and "keyDown" actions will no longer accept multiple characters for the "value". These actions are now limited to a single grapheme cluster to ensure consistent behavior.
In Firefox 131 we added support for the remaining arguments of the "network.continueResponse" command, such as cookies, headers, statusCode and reasonPhrase. This allows clients to modify cookies, headers, status codes (e.g., 200, 304), and status text (e.g., “OK”, “Not modified”) during the "responseStarted" phase, when a real network response is intercepted, while preserving the response body.
-> { "method": "network.continueResponse", "params": { "request": "12", "headers": [ { "name": "test-header", "value": { "type": "string", "value": "42" } } ], "reasonPhrase": "custom status text", "statusCode": 404 }, "id": 2 } <- { "type": "success", "id": 2, "result": {} } Bug fixes- The "browsingContext.navigate" command will now return if the "wait" argument is "none" and a beforeunload prompt is triggered.
- The "browsingContext.navigate" command will now return an "unknown error" in all cases where a navigation failure occurs, as required by the specification.
- The "session.new" command will no longer include the "unhandledPromptBehavior" capability in its response if it was not specified by the client as an argument.
Wladimir Palant: Lies, damned lies, and Impact Hero (refoorest, allcolibri)
Transparency note: According to Colibri Hero, they attempted to establish a business relationship with eyeo, a company that I co-founded. I haven’t been in an active role at eyeo since 2018, and I left the company entirely in 2021. Colibri Hero was only founded in 2021. My investigation here was prompted by a blog comment.
Colibri Hero (also known as allcolibri) is a company with a noble mission:
We want to create a world where organizations can make a positive impact on people and communities.
One of the company’s products is the refoorest browser extension, promising to make a positive impact on the climate by planting trees. Best of it: this costs users nothing whatsoever. According to the refoorest website:
Plantation financed by our partners
So the users merely need to have the extension installed, indicating that they want to make a positive impact. And since the concept was so successful, Colibri Hero recently turned it into an SDK called Impact Hero (also known as Impact Bro), so that it could be added to other browser extensions.
What the company carefully avoids mentioning: its 56,000 “partners” aren’t actually aware that they are financing tree planting. The refoorest extension and extensions using the Impact Hero SDK automatically open so-called affiliate links in the browser, making certain that the vendor pays them an affiliate commission for whatever purchases the users make. As the extensions do nothing to lead users to a vendor’s offers, this functionality likely counts as affiliate fraud.
The refoorest extension also makes very clear promises to its users: planting a tree for each extension installation, two trees for an extension review as well as a tree for each vendor visit. Clearly, this is not actually happening according to the numbers published by Colibri Hero themselves.
What does happen is careless handling of users’ data despite the “100% Data privacy guaranteed” promise. In fact, the company didn’t even bother to produce a proper privacy policy. There are various shady practices including a general lack of transparency, with the financials never disclosed. As proof of trees being planted the company links to a “certificate” which is … surprise! … its own website.
Mind you, I’m not saying that the company is just pocketing the money it receives via affiliate commissions. Maybe they are really paying Eden Reforestation (not actually called that any more) to plant trees and the numbers they publish are accurate. As a user, this is quite a leap of faith with a company that shows little commitment to facts and transparency however.
Contents- What is Colibri Hero?
- And what about refoorest?
- The newcomer: Impact Hero
- Affected extensions
- But are they actually planting trees?
- The privacy commitment
- Happy users
- Security issue
- Conclusions
Let’s get our facts straight. First of all, what is Colibri Hero about? To quote their mission statement:
Because more and more companies are getting involved in social and environmental causes, we have created a SaaS solution that helps brands and organizations bring impactful change to the environment and communities in need, with easy access to data and results. More than that, our technology connects companies and non-profit organizations together to generate real impact.
Our e-solution brings something new to the demand for corporate social responsibility: brands and organizations can now offer their customers and employees the chance to make a tangible impact, for free. An innovative way to create an engaged community that feels empowered and rewarded.
You don’t get it? Yes, it took me a while to understand as well.
This is about companies’ bonus programs. Like: you make a purchase, you get ten points for the company’s loyalty program. Once you have a few hundred of those points, you can convert them into something tangible: getting some product for free or at a discount.
And Colibri Hero’s offer is: the company can offer people to donate those points, for a good cause. Like planting trees or giving out free meals or removing waste from the oceans. It’s a win-win situation: people can feel good about themselves, the company saves themselves some effort and Colibri Hero receives money that they can forward to social projects (after collecting their commission of course).
I don’t know whether the partners get any proof of money being donated other than the overview on the Colibri Hero website. At least I could not find any independent confirmation of it happening. All photos published by the company are generic and from unrelated events. Except one: there is photographic proof that some notebooks (as in: paper that you write on) have been distributed to girls in Sierra Leone.
Few Colibri Hero partners report the impact of this partnership or even its existence. The numbers are public on Colibri Hero website however if you know where to look for them and who those partners are. And since Colibri Hero left the directory index enabled for their Google Storage bucket, the logos of their partners are public as well.
So while Colibri Hero never published a transparency report themselves, it’s clear that they partnered up with less than 400 companies. Most of these partnerships appear to have never gone beyond a trial, the impact numbers are negligible. And despite Colibri Hero boasting their partnerships with big names like Decathlon and Foot Locker, the corresponding numbers are rather underwhelming for the size of these businesses.
Colibri Hero runs a shop which they don’t seem to link anywhere but which gives a rough impression of what they charge their partners. Combined with the public impact numbers (mind you, these have been going since the company was founded in 2021), this impression condenses into revenue numbers far too low to support a company employing six people in France, not counting board members and ethics advisors.
And what about refoorest?This is likely where the refoorest extension comes in. While given the company’s mission statement this browser extension with its less than 100,000 users across all platforms (most of them on Microsoft Edge) sounds like a side hustle, it should actually be the company’s main source of income.
The extension’s promise sounds very much like that of the Ecosia search engine: you search the web, we plant trees. Except that with Ecosia you have to use their search engine while refoorest supports any search engine (as well as Linkedin and Twitter/X which they don’t mention explicitly). Suppose you are searching for a new pair of pants on Google. One of the search results is Amazon. With refoorest you see this:

If you click the search result you go to Amazon as usual. Clicking that added link above the search result however will send you to the refoorest.com domain, where you will be redirected to the v2i8b.com domain (an affiliate network) which will in turn redirect you to amazon.com (the main page, not the pants one). And your reward for that effort? One more tree added to your refoorest account! Planting trees is really easy, right?
One thing is odd about this extension’s listing on Chrome Web Store: for an extension with merely 20,000 users, 2.9K ratings is a lot.

One reason is: the extension incentivizes leaving reviews. This is what the extension’s pop-up looks like:

Review us and we will plant two trees! Give us your email address and we will plant another two trees! Invite fifteen friends and we will plant a whole forest for you!
The newcomer: Impact HeroGiven the success of refoorest, it’s unsurprising that the company is looking for ways to expand this line of business. What they recently came up with is the Impact Hero SDK, or Impact Bro as its website calls it (yes, really). It adds an “eco-friendly mode” to existing extensions. To explain it with the words of the Impact Bros (highlighting of original):
With our eco-friendly mode, you can effortlessly plant trees and offset carbon emissions at no cost as you browse the web. This allows us to improve the environmental friendliness of our extension.
Wow, that’s quite something, right? And how is that possible? That’s explained a little further in the text:
Upon visiting one of these merchant partners, you’ll observe a brief opening of a new tab. This tab facilitates the calculation of the required carbon offset.
Oh, calculation of the required carbon offset, makes sense. That’s why it loads the same website that I’m visiting but via an affiliate network. Definitely not to collect an affiliate commission for my purchases.
Just to make it very clear: the thing about calculating carbon offsets is a bold lie. This SDK earns money via affiliate commissions, very much in the same way as the refoorest extension. But rather than limiting itself to search results and users’ explicit clicks on their link, it will do this whenever the user visits some merchant website.
Now this is quite unexpected functionality. Yet Chrome Web Store program policies require the following:
All functionalities of extensions should be clearly disclosed to the user, with no surprises.
Good that the Impact Hero SDK includes a consent screen, right? Here is what it looks like in the Chat GPT extension:

Yes, this doesn’t really help users make an informed decision. And if you think that the “Learn more” link helps, it leads to the page where I copied the “calculation of the required carbon offset” bullshit from.
The whole point of this “consent screen” seems to be tricking you into granting the extension access to all websites. Consequently, this consent screen is missing from extensions that already have access to all websites out of the box (including the two extensions owned by Colibri Hero themselves).
There is one more area that Colibri Hero focuses on to improve its revenue: their list of merchants that the extensions download each hour. This discussion puts the size of the list at 50 MB on September 6. When I downloaded it on September 17 it was already 62 MB big. By September 28 the list has grown to 92 MB. If this size surprises you: there are lots of duplicate entries. amazon.com alone is present 615 times in that list (some metadata differs, but the extensions don’t process that metadata anyway).
Affected extensionsIn addition to refoorest I could identify two extensions bought by Colibri Hero from their original author as well as 14 extensions which apparently added Impact Hero SDK expecting their share of the revenue. That’s Chrome Web Store only, the refoorest extension at the very least also exists in various other extension stores, even though it has been removed from Firefox Add-ons just recently.
Here is the list of extensions I found and their current Chrome Web Store stats:
Name Weekly active users Extension ID Bittorent For Chrome 40,000 aahnibhpidkdaeaplfdogejgoajkjgob Pro Sender - Free Bulk Message Sender 20,000 acfobeeedjdiifcjlbjgieijiajmkang Memory Match Game 7,000 ahanamijdbohnllmkgmhaeobimflbfkg Turbo Lichess - Best Move Finder 6,000 edhicaiemcnhgoimpggnnclhpgleakno TTV Adblock Plus 100,000 efdkmejbldmccndljocbkmpankbjhaao CoPilot™ Extensions For Chrome 10,000 eodojedcgoicpkfcjkhghafoadllibab Local Video-Audio Player 10,000 epbbhfcjkkdbfepjgajhagoihpcfnphj AI Shop Buddy 4,000 epikoohpebngmakjinphfiagogjcnddm Chat GPT 700,000 fnmihdojmnkclgjpcoonokmkhjpjechg GPT Chat 10,000 jncmcndmaelageckhnlapojheokockch Online-Offline MS Paint Tool 30,000 kadfogmkkijgifjbphojhdkojbdammnk refoorest: plant trees for free 20,000 lfngfmpnafmoeigbnpdfgfijmkdndmik Reader Mode 300,000 llimhhconnjiflfimocjggfjdlmlhblm ChatGPT 4 20,000 njdepodpfikogbbmjdbebneajdekhiai VB Sender - Envio em massa 1,000 nnclkhdpkldajchoopklaidbcggaafai ChatGPT to Notion 70,000 oojndninaelbpllebamcojkdecjjhcle Listen On Repeat YouTube Looper 30,000 pgjcgpbffennccofdpganblbjiglnbipEdit (2024-10-01): Opera already removed refoorest from their add-on store.
But are they actually planting trees?That’s a very interesting question, glad you asked. See, refoorest considers itself to be in direct competition with the Ecosia search engine. And Ecosia publishes detailed financial reports where they explain how much money they earn and where it went. Ecosia is also listed as a partner on the Eden: People+Planet website, so we have independent confirmation here that they in fact donated at least a million US dollars.
I searched quite thoroughly for comparable information on Colibri Hero. All I could find was this statement:
We allocate a portion of our income to operating expenses, including team salaries, social charges, freelancer payments, and various fees (such as servers, technical services, placement fees, and rent). Additionally, funds are used for communications to maximize the service’s impact. Then, 80% of the profits are donated to global reforestation projects through our partner, Eden Reforestation.
While this sounds good in principle, we have no idea how high their operational expenses are. Maybe they are donating half of their revenue, maybe none. Even if this 80% rule is really followed, it’s easy to make operational expenses (like the salary of the company founders) so high that there is simply no profit left.
Edit (2024-10-01): It seems that I overlooked them in the list of partners. So they did in fact donate at least 50 thousand US dollars. Thanks to Adrien de Malherbe of Colibri Hero for pointing this out. Edit (2024-10-02): According to the Internet Archive, refoorest got listed here in May 2023 and they have been in the “$50,000 - $99,999” category ever since. They were never listed with a smaller donation, and they never moved up either – almost like this was a one-time donation. As of October 2024, the Eden: People+Planet website puts the cost of planting a tree at $0.75.
And other than that they link to the certificate of the number of trees planted:

But that’s their own website, just like the maps of where trees are being planted. They can make it display any number.
Now you are probably thinking: “Wladimir, why are you so paranoid? You have no proof that they are lying, just trust them to do the right thing. It’s for a good cause!” Well, actually…
Remember that the refoorest extension promises its users to plant a specific number of trees? One for each extension installation, two for a review, one more tree each time a merchant website is visited? What do you think, how many trees came together this way?
One thing about Colibri Hero is: they don’t seem to be very fond of protecting data access. Not only their partners’ stats are public, the user data is as well. When the extension loads or updates the user’s data, there is no authentication whatsoever. Anybody can just open my account’s data in their browser provided that they know my user ID:

So anybody can track my progress – how many trees I’ve got, when the extension last updated my data, that kind of thing. Any stalkers around? Older data (prior to May 2022) even has an email field, though this one was empty for the accounts I saw.
How you might get my user ID? Well, when the extension asks me to promote it on social networks and to my friends, these links contain my user ID. There are plenty of such links floating around. But as long as you aren’t interested in a specific user: the user IDs are incremental. They are even called row_index in the extension source code.
See that index value in my data? We now know that 2,834,418 refoorest accounts were created before I decided to take a look. Some of these accounts certainly didn’t live long, yet the average still seems to be beyond 10 trees. But even ignoring that: two million accounts are two million trees just for the install.
According to their own numbers refoorest planted less that 700,000 trees, far less than those accounts “earned.” In other words: when these users were promised real physical trees, that was a lie. They earned virtual points to make them feel good, when the actual count of trees planted was determined by the volume of affiliate commissions.
Wait, was it actually determined by the affiliate commissions? We can get an idea by looking at the historical data for the number of planted trees. While Colibri Hero doesn’t provide that history, the refoorest website was captured by the Internet Archive at a significant number of points in time. I’ve collected the numbers and plotted them against the respective date. Nothing fancy like line smoothing, merely lines connecting the dots:

Well, that’s a straight line. There is a constant increase rate of around 20 trees per hour here. And I hate to break it to you, a graph like that is rather unlikely to depend on anything related to the extension which certainly grew its user base over the course of these four years.
There are only two anomalies here where the numbers changed non-linearly. There is a small jump end of January or start of February 2023. And there is a far larger jump later in 2023 after a three month period where the Internet Archive didn’t capture any website snapshots, probably because the website was inaccessible. When it did capture the number again it was already above 500,000.
The privacy commitmentRefoorest website promises:
100% Data privacy guaranteed
The Impact Hero SDK explainer promises:
This new feature does not retain any information or data, ensuring 100% compliance with GDPR laws.
Ok, let’s first take a look at their respective privacy policies. Here is the refoorest privacy policy:

If you find that a little bit hard to read, that’s because whoever copied that text didn’t bother to format lists and such. Maybe better to read it on the Impact Bro website?

Sorry, that’s even worse. Not even the headings are formatted here.
Either way, nothing shows appreciation for privacy like a standard text which is also used by pizza restaurants and similarly caring companies. Note how that references “Law No. 78-17 of 6 January 1978”? That’s some French data protection law that I’m pretty certain is superseded by GDPR. A reminder: GDPR came in effect in 2018, three years before Colibri Hero was even founded.
This privacy policy isn’t GDPR-compliant either. For example, it has no mention of consumer rights or who to contact if I want my data to be removed.
Data like what’s stored in those refoorest accounts which happen to be publicly visible. Some refoorest users might actually find that fact unexpected.
Or data like the email address that the extension promises two trees for. Wait, they don’t actually have that one. The email address goes straight to Poptin LTD, a company registered in Israel. There is no verification that the user owns the address like double opt-in. But at least Poptin has a proper GDPR-compliant privacy policy.
There is plenty of tracking going on all around refoorest, with data being collected by Cloudflare, Google, Facebook and others. This should normally be explained in the privacy policy. Well, not in this one.
Granted, there is less tracking around the Impact Hero SDK, still a far shot away from the “not retain any information or data” promise however. The “eco-friendly mode” explainer loads Google Tag Manager. The affiliate networks that extensions trigger automatically collect data, likely creating profiles of your browsing. And finally: why is each request going through a Colibri Hero website before redirecting to the affiliate network if no data is being collected there?
Happy usersWe’ve already seen that a fair amount of users leaving a review for the refoorest extension have been incentivized to do so. That’s the reason for “insightful” reviews like this one:

Funny enough, several of them then complain about not receiving their promised trees. That’s due to an extension issue: the extension doesn’t actually track whether somebody writes a review, it simply adds two trees with a delay after the “Leave a review” button is clicked. A bug in the code makes it “forget” that it meant to do this if something else happens in between. Rather that fixing the bug they removed the delay in the current extension version. The issue is still present when you give them your email address though.
But what about the user testimonies on their webpage?

Yes, this sounds totally like something real users would say, definitely not written by a marketing person. And these user photos definitely don’t come from something like the Random User Generator. Oh wait, they do.
In that context it makes sense that one of the company’s founders engages with the users in a blog titled “Eco-Friendly Living” where he posts daily articles with weird ChatGPT-generated images. According to metadata, all articles have been created on the same date, and each article took around four minutes – he must be a very fast typer. Every article presents a bunch of brands, and the only thing (currently) missing to make the picture complete are affiliate links.
Security issueIt’s not like the refoorest extension or the SDK do much. Given that, the company managed to produce a rather remarkable security issue. Remember that their links always point to a Colibri Hero website first, only to be redirected to the affiliate network then? Well, for some reason they thought that performing this redirect in the extension was a good idea.
So their extension and their SDK do the following:
if (window.location.search.indexOf("partnerurl=") > -1) { const url = decodeURIComponent(gup("partnerurl", location.href)); location.href = url; return; }Found a partnerurl parameter in the query string? Redirect to it! You wonder what websites this code is active on? All of them of course! What could possibly go wrong…
Well, the most obvious thing to go wrong is: this might be a javascript: URL. A malicious website could open https://example.com/?partnerurl=javascript:alert(1) and the extension will happily navigate to that URL. This almost became a Universal Cross-Site Scripting (UXSS) vulnerability. Luckily, the browser prevents this JavaScript code from running, at least with Manifest V3.
It’s likely that the same vulnerability already existed in the refoorest extension back when it was using Manifest V2. At that point it was a critical issue. It’s only with the improvements in Manifest V3 that extensions’ content scripts are subject to a Content Security Policy which prevents execution of arbitrary Javascript code.
So now this is merely an open redirect vulnerability. It could be abused for example to disguise link targets and abuse trust relationships. A link like https://example.com/?partnerurl=https://evil.example.net/ looks like it would lead to a trusted example.com website. Yet the extension would redirect it to the malicious evil.example.net website instead.
ConclusionsWe’ve seen that Colibri Hero is systematically misleading extension users about the nature of its business. Users are supposed to feel good about doing something for the planet, and the entire communication suggests that the “partners” are contributing finances due to sharing this goal. The aspect of (ab)using the system of affiliate marketing is never disclosed.
This is especially damning in case of the refoorest extension where users are being incentivized by a number of trees supposedly planted as a result of their actions. At no point does Colibri Hero disclose that this number is purely virtual, with the actual count of trees planted being far lower and depending on entirely different factors. Or rather no factors at all if their reported numbers are to be trusted, with the count of planted trees always increasing at a constant rate.
For the Impact Hero SDK this misleading communication is paired with clearly insufficient user consent. Most extensions don’t ask for user consent at all, and those that do aren’t allowing an informed decision. The consent screen is merely a pretense to trick the users into granting extended permissions.
This by itself is already in gross violation of the Chrome Web Store policies and warrants a takedown action. Other add-on stores have similar rules, and Mozilla in fact already removed the refoorest extension prior to my investigation.
Colibri Hero additionally shows a pattern of shady behavior, such as quoting fake user testimonies, referring to themselves as “proof” of their beneficial activity and a general lack of transparency about finances. None of this is proof that this company isn’t donating money as it claims to do, but it certainly doesn’t help trusting them with it.
The technical issues and neglect for users’ privacy are merely a sideshow here. These are somewhat to be expected for a small company with limited financing. Even a small company can do better however if the priorities are aligned.
Mozilla Thunderbird: Help Us Test the Thunderbird for Android Beta!

The Thunderbird for Android beta is out and we’re asking our community to help us test it. Beta testing helps us find critical bugs and rough edges that we can polish in the next few weeks. The more people who test the beta and ensure everything in the testing checklist works correctly, the better!
Help Us Test!Anyone can be a beta tester! Whether you’re an experienced beta tester or you’ve never tested a beta image before, we want to make it easy for you. We are grateful for your time and energy, so we aim to make testing quick, efficient, and hopefully fun!!
The release plan is as follows, and we hope to stick to this timeline unless we encounter any major hurdles:
- September 30 – First beta for Thunderbird for Android
- Third week of October – first release candidate
- Fourth week of October – Thunderbird for Android release
Below are the options for where you can download with Beta and get started:
- Download Thunderbird Beta on the Google Play Store
- Download the latest pre-release version from our Github Releases page
We are still working on preparing F-Droid builds. In the meanwhile, please make use of the other two download mechanisms.
Use the Testing ChecklistOnce you’ve downloaded the Thunderbird for Android beta, we’d like you to check that you can do the following:
- Automatic Setup (user only provides email address and maybe password)
- Manual Setup (user provides server settings)
- Read Messages
- Fetch Messages
- Switch accounts
- Move email to folder
- Notify for new message
- Edit drafts
- Write message
- Send message
- Email actions: reply, forward
- Delete email
- NOT experience data loss
If you’re already using K-9 Mail, you can help test an important feature: transferring your data from K-9 Mail to Thunderbird for Android. To do this, you’ll need to make sure you’ve upgraded to the latest beta version of K-9 Mail.
This transfer process is a key step in making it easier for K-9 Mail users to move over to Thunderbird. Testing this will help ensure a smooth and reliable experience for future users making the switch.
Later builds will additionally include a way to transfer your information from Thunderbird Desktop to Thunderbird for Android.
What we’re not testingWe know it’s tempting to comment about everything you notice in the beta. For the purpose of this short initial beta, we won’t be focusing on addressing longstanding issues. Instead, we ask you to be laser focused on critical bugs, the checklist above, and issues could prevent users from effectively interacting with the app, to help us deliver a great initial release.
Where to Give FeedbackShare your feedback on the Thunderbird for Android beta mailing list and see the feedback of other users. It’s easy to sign up and let us know what worked and more importantly, what didn’t work from the tasks above. For bug reports, please provide as much detail as possible including steps to reproduce the issue, your device model and OS version, and any relevant screenshots or error messages.
Want to chat with other community members, including other testers and contributors working on Thunderbird for Android? Join us on Matrix!
Do you have ideas you would like to see in future versions of Thunderbird for Android? Let us know on Mozilla Connect, our official site to submit and upvote ideas.
The post Help Us Test the Thunderbird for Android Beta! appeared first on The Thunderbird Blog.
Wil Clouser: PyFxA 0.7.9 Released
We released PyFxA 0.7.9 last week (pypi). This added:
- Support for key stretching v2. See the end of bug 1320222 for some details. V1 will continue to work, but we’ll remove support for it at some point in the future.
- Upgraded to support (and test!) Python 3
Special thanks to Rob Hudson and Dan Schomburg for thier efforts.
Don Marti: fair use alignment chart
Tantek Çelik suggests that Creative Commons should add a CC-NT license, like the existing Creative Commons licenses, but written to make it clear that the content is not licensed for generative AI training. Manton Reece likes the idea, and would allow training—but understands why publishers would choose not to. AI training permissions are becoming a huge deal, and there is a need for more licensing options. disclaimer: we’re taking steps in this area at work now. This is a personal blog post though, not speaking for employer or anyone else. In the 2024 AI Training Survey Results from Draft2Digital, only 5% of the authors surveyed said that scraping and training without a license is fair use.
Tantek links to the Creative Commons Position Paper on Preference Signals, which states,
Arguably, copyright is not the right framework for defining the rules of this newly formed ecosystem.
That might be a good point from the legal scholarship point of view, but the frequently expressed point of view of web people is more like, creepy bots are scraping my stuff, I’ll throw anything at them I can to get them to stop. Cloudflare’s one-click AI scraper blocker is catching on. For a lot of the web, the AI problem feels more like an emergency looting situation than an academic debate. AI training permissions will be a point where people just end up disagreeing, and where the Creative Commons approach to copyright, where the license deliberately limits the rights that a content creator can try to assert, is a bad fit for what many web people really want. People disagree on what is and isn’t fair use, and how far the power of copyright law should extend. And some free culture people who would prefer less powerful copyright laws in principle are not inclined to unilaterally refuse to use a tool that others are already using.
The techbro definition of fair use (what’s yours is open, what’s mine is proprietary) is clearly bogus, so we can safely ignore that—but it seems like Internet freedom people can be found along both axes of the fair use alignment chart. yes, there are four factors, but generative AI typically uses the entire work, so we can ignore the amount one, and we’re generally talking about human-created personal cultural works, so the nature of the copyrighted works we’re arguing about is generally similar. So we’re down to two, which is good because I don’t know how to make 3 and 4d tables in HTML.
Transformative purist: work must be signficantly transformed Transformative neutral: work must be somehow transformed Transformative chaotic: work may be transformed Market purist: work must not have a negative effect on the market for the original Memes are fair use AI business presentation assistants are fair use A verbatim quotation from a book in a book review is fair use Market neutral: work may have some effect on the market AI-generated ads are fair use AI slop blogs are fair use New Portraits is fair use Market chaotic: work may have significant effect on the market for the original AI illustrations that mimic an artist's style but not specific artworks are fair use Orange Prince is fair use Grok is fair useWe’re probably going to end up with alternate free culture licenses, which is a good thing. But it’s probably not realistic to get organizations to change their alignment too much. Free culture licensing is too good of an idea to keep with one licensing organization, just like free software foundations (lower case) are useful enough that it’s a good idea to have a redundant array of them.
Do we need a toothier, more practical license?This site is not licensed under a Creative Commons license, because I have some practical requirements that aren’t in one of the standard CC licenses. These probably apply to more sites than just this one. Personally, I would be happier with a toothier license that covers some of the reasons I don’t use CC now.
No permission for generative AI training (already covered this)
Licensee must preserve links when using my work in a medium where links work. I’m especially interested in preserving link rel=author and link rel=canonical. I would not mind giving general permission for copying and mirroring material from this site, except that SEO is a thing. Without some search engine signal, it would be too easy for a copy of my stuff on a higher-ranked site to make this site un-findable. I’m prepared to give up some search engine juice for giving out some material, just don’t want to get clobbered wholesale.
Patent license: similar to open-source software license terms. You can read my site but not use it for patent trolling. If you use my content, I get a license to any of your patents that would be infringed by making the content and operating the site.
Privacy flags: this site is licensed for human use, not for sale or sharing of personal info for behavioral targeting. I object to processing of any personal information that may be collected or inferred from this site.
In general, if I can’t pick a license that lets me make content available to people doing normal people stuff, but not to non-human entities with non-human goals, I will have to make the people ask me in person. Putting a page on the web can have interesting consequences, and a web-aware license that works for me will probably needs to color outside the lines of the ideal copyright law that would make sense if we were coming up with copyright laws from scratch.
Bonus linksKnowledge workers Taylor’s model of workplace productivity depended entirely on deskilling, on the invention of unskilled labor—which, heretofore, had not existed.
Reverse-engineering a three-axis attitude indicator from the F-4 fighter plane In a normal aircraft, the artificial horizon shows the orientation in two axes (pitch and roll), but the F-4 indicator uses a rotating ball to show the orientation in three axes, adding azimuth (yaw).
Grid-scale batteries: They’re not just lithium Alternatives to lithium-ion technology may provide environmental, labor, and safety benefits. And these new chemistries can work in markets like the electric grid and industrial applications that lithium doesn’t address well.
Zen and the art of Writer Decks (using the Pomera DM250) Probably as a direct result of the increasing spamminess of the internet in general and Windows 11 in its own right, over the past few years a market has emerged for WriterDecks—single purpose writing machines that include a keyboard (or your choice of keyboard), a screen, and some minimal distraction-free writing software.
Useful Idiots and Good Authoritarians Recycling some jokes here, but I think there’s something to be said for knowing an online illiberal’s favorite Good Authoritarian. Here’s what it says about them Related: With J.D. Vance on Trump ticket, the Nerd Reich goes national
Gamergate at 10 10 years later, the events of Gamergate remain a cipher through which it’s possible to understand a lot about our current sociocultural situation.
A Rose Diary Thanks to Mr. Austin these roses are now widely available and beautiful gardens around the world can be filled with roses that look like real roses and the smell of roses can be inhaled all over the world including on my own property.