
Ludovic Hirlimann: My geeking plans for this summer
During July I’ll be visiting family in Mongolia but I’ve also a few things that are very geeky that I want to do.
The first thing I want to do is plug the Ripe Atlas probes I have. It’s litle devices that look like that :

They enable anybody with a ripe atlas or ripe account to make measurements for dns queries and others. This helps making a global better internet. I have three of these probes I’d like to install. It’s good because last time I checked Mongolia didn’t have any active probe. These probes will also help Internet become better in Mongolia. I’ll need to buy some network cables before leaving because finding these in mongolia is going to be challenging. More on atlas at https://atlas.ripe.net/.
The second thing I intend to do is map Mongolia a bit better on two projects the first is related to Mozilla and maps gps coordinateswith wifi access point. Only a little part of The capital Ulaanbaatar is covered as per https://location.services.mozilla.com/map#11/47.8740/106.9485 I want this to be way more because having an open data source for this is important in the future. As mapping is my new thing I’ll probably edit Openstreetmap in order to make the urban parts of mongolia that I’ll visit way more usable on all the services that use OSM as a source of truth. There is already a project to map the capital city at http://hotosm.org/projects/mongolia_mapping_ulaanbaatar but I believe osm can server more than just 50% of mongolia’s population.
I got inspired to write this post by mu son this morning, look what he is doing at 17 months :

Andrew Sutherland: Talk Script: Firefox OS Email Performance Strategies
Last week I gave a talk at the Philly Tech Week 2015 Dev Day organized by the delightful people at technical.ly on some of the tricks/strategies we use in the Firefox OS Gaia Email app. Note that the credit for implementing most of these techniques goes to the owner of the Email app’s front-end, James Burke. Also, a special shout-out to Vivien for the initial DOM Worker patches for the email app.
I tried to avoid having slides that both I would be reading aloud as the audience read silently, so instead of slides to share, I have the talk script. Well, I also have the slides here, but there’s not much to them. The headings below are the content of the slides, except for the one time I inline some code. Note that the live presentation must have differed slightly, because I’m sure I’m much more witty and clever in person than this script would make it seem…
Cover Slide: Who!
Hi, my name is Andrew Sutherland. I work at Mozilla on the Firefox OS Email Application. I’m here to share some strategies we used to make our HTML5 app Seem faster and sometimes actually Be faster.
What’s A Firefox OS (Screenshot Slide)
But first: What is a Firefox OS? It’s a multiprocess Firefox gecko engine on an android linux kernel where all the apps including the system UI are implemented using HTML5, CSS, and JavaScript. All the apps use some combination of standard web APIs and APIs that we hope to standardize in some form.

Here are some screenshots. We’ve got the default home screen app, the clock app, and of course, the email app.
It’s an entirely client-side offline email application, supporting IMAP4, POP3, and ActiveSync. The goal, like all Firefox OS apps shipped with the phone, is to give native apps on other platforms a run for their money.
And that begins with starting up fast.
Fast Startup: The Problems
But that’s frequently easier said than done. Slow-loading websites are still very much a thing.
The good news for the email application is that a slow network isn’t one of its problems. It’s pre-loaded on the phone. And even if it wasn’t, because of the security implications of the TCP Web API and the difficulty of explaining this risk to users in a way they won’t just click through, any TCP-using app needs to be a cryptographically signed zip file approved by a marketplace. So we do load directly from flash.
However, it’s not like flash on cellphones is equivalent to an infinitely fast, zero-latency network connection. And even if it was, in a naive app you’d still try and load all of your HTML, CSS, and JavaScript at the same time because the HTML file would reference them all. And that adds up.
It adds up in the form of event loop activity and competition with other threads and processes. With the exception of Promises which get their own micro-task queue fast-lane, the web execution model is the same as all other UI event loops; events get scheduled and then executed in the same order they are scheduled. Loading data from an asynchronous API like IndexedDB means that your read result gets in line behind everything else that’s scheduled. And in the case of the bulk of shipped Firefox OS devices, we only have a single processor core so the thread and process contention do come into play.
So we try not to be a naive.
Seeming Fast at Startup: The HTML Cache
If we’re going to optimize startup, it’s good to start with what the user sees. Once an account exists for the email app, at startup we display the default account’s inbox folder.
What is the least amount of work that we can do to show that? Cache a screenshot of the Inbox. The problem with that, of course, is that a static screenshot is indistinguishable from an unresponsive application.
So we did the next best thing, (which is) we cache the actual HTML we display. At startup we load a minimal HTML file, our concatenated CSS, and just enough Javascript to figure out if we should use the HTML cache and then actually use it if appropriate. It’s not always appropriate, like if our application is being triggered to display a compose UI or from a new mail notification that wants to show a specific message or a different folder. But this is a decision we can make synchronously so it doesn’t slow us down.
Local Storage: Okay in small doses
We implement this by storing the HTML in localStorage.
Important Disclaimer! LocalStorage is a bad API. It’s a bad API because it’s synchronous. You can read any value stored in it at any time, without waiting for a callback. Which means if the data is not in memory the browser needs to block its event loop or spin a nested event loop until the data has been read from disk. Browsers avoid this now by trying to preload the Entire contents of local storage for your origin into memory as soon as they know your page is being loaded. And then they keep that information, ALL of it, in memory until your page is gone.
So if you store a megabyte of data in local storage, that’s a megabyte of data that needs to be loaded in its entirety before you can use any of it, and that hangs around in scarce phone memory.
To really make the point: do not use local storage, at least not directly. Use a library like localForage that will use IndexedDB when available, and then fails over to WebSQLDatabase and local storage in that order.
Now, having sufficiently warned you of the terrible evils of local storage, I can say with a sorta-clear conscience… there are upsides in this very specific case.
The synchronous nature of the API means that once we get our turn in the event loop we can act immediately. There’s no waiting around for an IndexedDB read result to gets its turn on the event loop.
This matters because although the concept of loading is simple from a User Experience perspective, there’s no standard to back it up right now. Firefox OS’s UX desires are very straightforward. When you tap on an app, we zoom it in. Until the app is loaded we display the app’s icon in the center of the screen. Unfortunately the standards are still assuming that the content is right there in the HTML. This works well for document-based web pages or server-powered web apps where the contents of the page are baked in. They work less well for client-only web apps where the content lives in a database and has to be dynamically retrieved.
The two events that exist are:
“DOMContentLoaded” fires when the document has been fully parsed and all scripts not tagged as “async” have run. If there were stylesheets referenced prior to the script tags, the script tags will wait for the stylesheet loads.
“load” fires when the document has been fully loaded; stylesheets, images, everything.
But none of these have anything to do with the content in the page saying it’s actually done. This matters because these standards also say nothing about IndexedDB reads or the like. We tried to create a standards consensus around this, but it’s not there yet. So Firefox OS just uses the “load” event to decide an app or page has finished loading and it can stop showing your app icon. This largely avoids the dreaded “flash of unstyled content” problem, but it also means that your webpage or app needs to deal with this period of time by displaying a loading UI or just accepting a potentially awkward transient UI state.
(Trivial HTML slide)
<link rel=”stylesheet” ...> <script ...></script> DOMContentLoaded!This is the important summary of our index.html.
We reference our stylesheet first. It includes all of our styles. We never dynamically load stylesheets because that compels a style recalculation for all nodes and potentially a reflow. We would have to have an awful lot of style declarations before considering that.
Then we have our single script file. Because the stylesheet precedes the script, our script will not execute until the stylesheet has been loaded. Then our script runs and we synchronously insert our HTML from local storage. Then DOMContentLoaded can fire. At this point the layout engine has enough information to perform a style recalculation and determine what CSS-referenced image resources need to be loaded for buttons and icons, then those load, and then we’re good to be displayed as the “load” event can fire.
After that, we’re displaying an interactive-ish HTML document. You can scroll, you can press on buttons and the :active state will apply. So things seem real.
Being Fast: Lazy Loading and Optimized Layers
But now we need to try and get some logic in place as quickly as possible that will actually cash the checks that real-looking HTML UI is writing. And the key to that is only loading what you need when you need it, and trying to get it to load as quickly as possible.
There are many module loading and build optimizing tools out there, and most frameworks have a preferred or required way of handling this. We used the RequireJS family of Asynchronous Module Definition loaders, specifically the alameda loader and the r-dot-js optimizer.
One of the niceties of the loader plugin model is that we are able to express resource dependencies as well as code dependencies.
RequireJS Loader Plugins
var fooModule = require('./foo'); var htmlString = require('text!./foo.html'); var localizedDomNode = require('tmpl!./foo.html');The standard Common JS loader semantics used by node.js and io.js are the first one you see here. Load the module, return its exports.
But RequireJS loader plugins also allow us to do things like the second line where the exclamation point indicates that the load should occur using a loader plugin, which is itself a module that conforms to the loader plugin contract. In this case it’s saying load the file foo.html as raw text and return it as a string.
But, wait, there’s more! loader plugins can do more than that. The third example uses a loader that loads the HTML file using the ‘text’ plugin under the hood, creates an HTML document fragment, and pre-localizes it using our localization library. And this works un-optimized in a browser, no compilation step needed, but it can also be optimized.
So when our optimizer runs, it bundles up the core modules we use, plus, the modules for our “message list” card that displays the inbox. And the message list card loads its HTML snippets using the template loader plugin. The r-dot-js optimizer then locates these dependencies and the loader plugins also have optimizer logic that results in the HTML strings being inlined in the resulting optimized file. So there’s just one single javascript file to load with no extra HTML file dependencies or other loads.
We then also run the optimizer against our other important cards like the “compose” card and the “message reader” card. We don’t do this for all cards because it can be hard to carve up the module dependency graph for optimization without starting to run into cases of overlap where many optimized files redundantly include files loaded by other optimized files.
Plus, we have another trick up our sleeve:
Seeming Fast: Preloading
Preloading. Our cards optionally know the other cards they can load. So once we display a card, we can kick off a preload of the cards that might potentially be displayed. For example, the message list card can trigger the compose card and the message reader card, so we can trigger a preload of both of those.
But we don’t go overboard with preloading in the frontend because we still haven’t actually loaded the back-end that actually does all the emaily email stuff. The back-end is also chopped up into optimized layers along account type lines and online/offline needs, but the main optimized JS file still weighs in at something like 17 thousand lines of code with newlines retained.
So once our UI logic is loaded, it’s time to kick-off loading the back-end. And in order to avoid impacting the responsiveness of the UI both while it loads and when we’re doing steady-state processing, we run it in a DOM Worker.
Being Responsive: Workers and SharedWorkers
DOM Workers are background JS threads that lack access to the page’s DOM, communicating with their owning page via message passing with postMessage. Normal workers are owned by a single page. SharedWorkers can be accessed via multiple pages from the same document origin.
By doing this, we stay out of the way of the main thread. This is getting less important as browser engines support Asynchronous Panning & Zooming or “APZ” with hardware-accelerated composition, tile-based rendering, and all that good stuff. (Some might even call it magic.)
When Firefox OS started, we didn’t have APZ, so any main-thread logic had the serious potential to result in janky scrolling and the impossibility of rendering at 60 frames per second. It’s a lot easier to get 60 frames-per-second now, but even asynchronous pan and zoom potentially has to wait on dispatching an event to the main thread to figure out if the user’s tap is going to be consumed by app logic and preventDefault called on it. APZ does this because it needs to know whether it should start scrolling or not.
And speaking of 60 frames-per-second…
Being Fast: Virtual List Widgets
…the heart of a mail application is the message list. The expected UX is to be able to fling your way through the entire list of what the email app knows about and see the messages there, just like you would on a native app.
This is admittedly one of the areas where native apps have it easier. There are usually list widgets that explicitly have a contract that says they request data on an as-needed basis. They potentially even include data bindings so you can just point them at a data-store.
But HTML doesn’t yet have a concept of instantiate-on-demand for the DOM, although it’s being discussed by Firefox layout engine developers. For app purposes, the DOM is a scene graph. An extremely capable scene graph that can handle huge documents, but there are footguns and it’s arguably better to err on the side of fewer DOM nodes.
So what the email app does is we create a scroll-region div and explicitly size it based on the number of messages in the mail folder we’re displaying. We create and render enough message summary nodes to cover the current screen, 3 screens worth of messages in the direction we’re scrolling, and then we also retain up to 3 screens worth in the direction we scrolled from. We also pre-fetch 2 more screens worth of messages from the database. These constants were arrived at experimentally on prototype devices.
We listen to “scroll” events and issue database requests and move DOM nodes around and update them as the user scrolls. For any potentially jarring or expensive transitions such as coordinate space changes from new messages being added above the current scroll position, we wait for scrolling to stop.
Nodes are absolutely positioned within the scroll area using their ‘top’ style but translation transforms also work. We remove nodes from the DOM, then update their position and their state before re-appending them. We do this because the browser APZ logic tries to be clever and figure out how to create an efficient series of layers so that it can pre-paint as much of the DOM as possible in graphic buffers, AKA layers, that can be efficiently composited by the GPU. Its goal is that when the user is scrolling, or something is being animated, that it can just move the layers around the screen or adjust their opacity or other transforms without having to ask the layout engine to re-render portions of the DOM.
When our message elements are added to the DOM with an already-initialized absolute position, the APZ logic lumps them together as something it can paint in a single layer along with the other elements in the scrolling region. But if we start moving them around while they’re still in the DOM, the layerization logic decides that they might want to independently move around more in the future and so each message item ends up in its own layer. This slows things down. But by removing them and re-adding them it sees them as new with static positions and decides that it can lump them all together in a single layer. Really, we could just create new DOM nodes, but we produce slightly less garbage this way and in the event there’s a bug, it’s nicer to mess up with 30 DOM nodes displayed incorrectly rather than 3 million.
But as neat as the layerization stuff is to know about on its own, I really mention it to underscore 2 suggestions:
1, Use a library when possible. Getting on and staying on APZ fast-paths is not trivial, especially across browser engines. So it’s a very good idea to use a library rather than rolling your own.
2, Use developer tools. APZ is tricky to reason about and even the developers who write the Async pan & zoom logic can be surprised by what happens in complex real-world situations. And there ARE developer tools available that help you avoid needing to reason about this. Firefox OS has easy on-device developer tools that can help diagnose what’s going on or at least help tell you whether you’re making things faster or slower:
– it’s got a frames-per-second overlay; you do need to scroll like mad to get the system to want to render 60 frames-per-second, but it makes it clear what the net result is
– it has paint flashing that overlays random colors every time it paints the DOM into a layer. If the screen is flashing like a discotheque or has a lot of smeared rainbows, you know something’s wrong because the APZ logic is not able to to just reuse its layers.
– devtools can enable drawing cool colored borders around the layers APZ has created so you can see if layerization is doing something crazy
There’s also fancier and more complicated tools in Firefox and other browsers like Google Chrome to let you see what got painted, what the layer tree looks like, et cetera.
And that’s my spiel.
Links
The source code to Gaia can be found at https://github.com/mozilla-b2g/gaia
The email app in particular can be found at https://github.com/mozilla-b2g/gaia/tree/master/apps/email
(I also asked for questions here.)
Joshua Cranmer: Breaking news
The primary fear, it seems, is that knowledge that the largest open-source email client was still receiving regular updates would impel its userbase to agitate for increased funding and maintenance of the client to help forestall potential threats to the open nature of email as well as to innovate in the space of providing usable and private communication channels. Such funding, however, would be an unaffordable luxury and would only distract Mozilla from its central goal of building developer productivity tooling. Persistent rumors that Mozilla would be willing to fund Thunderbird were it renamed Firefox Email were finally addressed with the comment, "such a renaming would violate our current policy that all projects be named Persona."
Joshua Cranmer: Why email is hard, part 8: why email security failed
At the end of the last part in this series, I posed the question, "Which email security protocol is most popular?" The answer to the question is actually neither S/MIME nor PGP, but a third protocol, DKIM. I haven't brought up DKIM until now because DKIM doesn't try to secure email in the same vein as S/MIME or PGP, but I still consider it relevant to discussing email security.
Unquestionably, DKIM is the only security protocol for email that can be considered successful. There are perhaps 4 billion active email addresses [1]. Of these, about 1-2 billion use DKIM. In contrast, S/MIME can count a few million users, and PGP at best a few hundred thousand. No other security protocols have really caught on past these three. Why did DKIM succeed where the others fail?
DKIM's success stems from its relatively narrow focus. It is nothing more than a cryptographic signature of the message body and a smattering of headers, and is itself stuck in the DKIM-Signature header. It is meant to be applied to messages only on outgoing servers and read and processed at the recipient mail server—it completely bypasses clients. That it bypasses clients allows it to solve the problem of key discovery and key management very easily (public keys are stored in DNS, which is already a key part of mail delivery), and its role in spam filtering is strong motivation to get it implemented quickly (it is 7 years old as of this writing). It's also simple: this one paragraph description is basically all you need to know [2].
The failure of S/MIME and PGP to see large deployment is certainly a large topic of discussion on myriads of cryptography enthusiast mailing lists, which often like to partake in propositions of new end-to-end encryption of email paradigms, such as the recent DIME proposal. Quite frankly, all of these solutions suffer broadly from at least the same 5 fundamental weaknesses, and I see it unlikely that a protocol will come about that can fix these weaknesses well enough to become successful.
The first weakness, and one I've harped about many times already, is UI. Most email security UI is abysmal and generally at best usable only by enthusiasts. At least some of this is endemic to security: while it mean seem obvious how to convey what an email signature or an encrypted email signifies, how do you convey the distinctions between sign-and-encrypt, encrypt-and-sign, or an S/MIME triple wrap? The Web of Trust model used by PGP (and many other proposals) is even worse, in that inherently requires users to do other actions out-of-band of email to work properly.
Trust is the second weakness. Consider that, for all intents and purposes, the email address is the unique identifier on the Internet. By extension, that implies that a lot of services are ultimately predicated on the notion that the ability to receive and respond to an email is a sufficient means to identify an individual. However, the entire purpose of secure email, or at least of end-to-end encryption, is subtly based on the fact that other people in fact have access to your mailbox, thus destroying the most natural ways to build trust models on the Internet. The quest for anonymity or privacy also renders untenable many other plausible ways to establish trust (e.g., phone verification or government-issued ID cards).
Key discovery is another weakness, although it's arguably the easiest one to solve. If you try to keep discovery independent of trust, the problem of key discovery is merely picking a protocol to publish and another one to find keys. Some of these already exist: PGP key servers, for example, or using DANE to publish S/MIME or PGP keys.
Key management, on the other hand, is a more troubling weakness. S/MIME, for example, basically works without issue if you have a certificate, but managing to get an S/MIME certificate is a daunting task (necessitated, in part, by its trust model—see how these issues all intertwine?). This is also where it's easy to say that webmail is an unsolvable problem, but on further reflection, I'm not sure I agree with that statement anymore. One solution is just storing the private key with the webmail provider (you're trusting them as an email client, after all), but it's also not impossible to imagine using phones or flash drives as keystores. Other key management factors are more difficult to solve: people who lose their private keys or key rollover create thorny issues. There is also the difficulty of managing user expectations: if I forget my password to most sites (even my email provider), I can usually get it reset somehow, but when a private key is lost, the user is totally and completely out of luck.
Of course, there is one glaring and almost completely insurmountable problem. Encrypted email fundamentally precludes certain features that we have come to take for granted. The lesser known is server-side search and filtration. While there exist some mechanisms to do search on encrypted text, those mechanisms rely on the fact that you can manipulate the text to change the message, destroying the integrity feature of secure email. They also tend to be fairly expensive. It's easy to just say "who needs server-side stuff?", but the contingent of people who do email on smartphones would not be happy to have to pay the transfer rates to download all the messages in their folder just to find one little email, nor the energy costs of doing it on the phone. And those who have really large folders—Fastmail has a design point of 1,000,000 in a single folder—would still prefer to not have to transfer all their mail even on desktops.
The more well-known feature that would disappear is spam filtration. Consider that 90% of all email is spam, and if you think your spam folder is too slim for that to be true, it's because your spam folder only contains messages that your email provider wasn't sure were spam. The loss of server-side spam filtering would dramatically increase the cost of spam (a 10% reduction in efficiency would double the amount of server storage, per my calculations), and client-side spam filtering is quite literally too slow [3] and too costly (remember smartphones? Imagine having your email take 10 times as much energy and bandwidth) to be a tenable option. And privacy or anonymity tends to be an invitation to abuse (cf. Tor and Wikipedia). Proposed solutions to the spam problem are so common that there is a checklist containing most of the objections.
When you consider all of those weaknesses, it is easy to be pessimistic about the possibility of wide deployment of powerful email security solutions. The strongest future—all email is encrypted, including metadata—is probably impossible or at least woefully impractical. That said, if you weaken some of the assumptions (say, don't desire all or most traffic to be encrypted), then solutions seem possible if difficult.
This concludes my discussion of email security, at least until things change for the better. I don't have a topic for the next part in this series picked out (this part actually concludes the set I knew I wanted to discuss when I started), although OAuth and DMARC are two topics that have been bugging me enough recently to consider writing about. They also have the unfortunate side effect of being things likely to see changes in the near future, unlike most of the topics I've discussed so far. But rest assured that I will find more difficulties in the email infrastructure to write about before long!
[1] All of these numbers are crude estimates and are accurate to only an order of magnitude. To justify my choices: I assume 1 email address per Internet user (this overestimates the developing world and underestimates the developed world). The largest webmail providers have given numbers that claim to be 1 billion active accounts between them, and all of them use DKIM. S/MIME is guessed by assuming that any smartcard deployment supports S/MIME, and noting that the US Department of Defense and Estonia's digital ID project are both heavy users of such smartcards. PGP is estimated from the size of the strong set and old numbers on the reachable set from the core Web of Trust.
[2] Ever since last April, it's become impossible to mention DKIM without referring to DMARC, as a result of Yahoo's controversial DMARC policy. A proper discussion of DMARC (and why what Yahoo did was controversial) requires explaining the mail transmission architecture and spam, however, so I'll defer that to a later post. It's also possible that changes in this space could happen within the next year.
[3] According to a former GMail spam employee, if it takes you as long as three minutes to calculate reputation, the spammer wins.
Joshua Cranmer: A unified history for comm-central
The first step and probably the hardest is getting the CVS history in DVCS form (I use hg because I'm more comfortable it, but there's effectively no difference between hg, git, or bzr here). There is a git version of mozilla's CVS tree available, but I've noticed after doing research that its last revision is about a month before the revision I need for Calendar's import. The documentation for how that repo was built is no longer on the web, although we eventually found a copy after I wrote this post on git.mozilla.org. I tried doing another conversion using hg convert to get CVS tags, but that rudely blew up in my face. For now, I've filed a bug on getting an official, branchy-and-tag-filled version of this repository, while using the current lack of history as a base. Calendar people will have to suffer missing a month of history.
CVS is famously hard to convert to more modern repositories, and, as I've done my research, Mozilla's CVS looks like it uses those features which make it difficult. In particular, both the calendar CVS import and the comm-central initial CVS import used a CVS tag HG_COMM_INITIAL_IMPORT. That tagging was done, on only a small portion of the tree, twice, about two months apart. Fortunately, mailnews code was never touched on CVS trunk after the import (there appears to be one commit on calendar after the tagging), so it is probably possible to salvage a repository-wide consistent tag.
The start of my script for conversion looks like this:
#!/bin/bash set -e WORKDIR=/tmp HGCVS=$WORKDIR/mozilla-cvs-history MC=/src/trunk/mozilla-central CC=/src/trunk/comm-central OUTPUT=$WORKDIR/full-c-c # Bug 445146: m-c/editor/ui -> c-c/editor/ui MC_EDITOR_IMPORT=d8064eff0a17372c50014ee305271af8e577a204 # Bug 669040: m-c/db/mork -> c-c/db/mork MC_MORK_IMPORT=f2a50910befcf29eaa1a29dc088a8a33e64a609a # Bug 1027241, bug 611752 m-c/security/manager/ssl/** -> c-c/mailnews/mime/src/* MC_SMIME_IMPORT=e74c19c18f01a5340e00ecfbc44c774c9a71d11d # Step 0: Grab the mozilla CVS history. if [ ! -e $HGCVS ]; then hg clone git+https://github.com/jrmuizel/mozilla-cvs-history.git $HGCVS fiSince I don't want to include the changesets useless to comm-central history, I trimmed the history by using hg convert to eliminate changesets that don't change the necessary files. Most of the files are simple directory-wide changes, but S/MIME only moved a few files over, so it requires a more complex way to grab the file list. In addition, I also replaced the % in the usernames with @ that they are used to appearing in hg. The relevant code is here:
# Step 1: Trim mozilla CVS history to include only the files we are ultimately # interested in. cat >$WORKDIR/convert-filemap.txt <<EOF # Revision e4f4569d451a include directory/xpcom include mail include mailnews include other-licenses/branding/thunderbird include suite # Revision 7c0bfdcda673 include calendar include other-licenses/branding/sunbird # Revision ee719a0502491fc663bda942dcfc52c0825938d3 include editor/ui # Revision 52efa9789800829c6f0ee6a005f83ed45a250396 include db/mork/ include db/mdb/ EOF # Add the S/MIME import files hg -R $MC log -r "children($MC_SMIME_IMPORT)" \ --template "{file_dels % 'include {file}\n'}" >>$WORKDIR/convert-filemap.txt if [ ! -e $WORKDIR/convert-authormap.txt ]; then hg -R $HGCVS log --template "{email(author)}={sub('%', '@', email(author))}\n" \ | sort -u > $WORKDIR/convert-authormap.txt fi cd $WORKDIR hg convert $HGCVS $OUTPUT --filemap convert-filemap.txt -A convert-authormap.txtThat last command provides us the subset of the CVS history that we need for unified history. Strictly speaking, I should be pulling a specific revision, but I happen to know that there's no need to (we're cloning the only head) in this case. At this point, we now need to pull in the mozilla-central changes before we pull in comm-central. Order is key; hg convert will only apply the graft points when converting the child changeset (which it does but once), and it needs the parents to exist before it can do that. We also need to ensure that the mozilla-central graft point is included before continuing, so we do that, and then pull mozilla-central:
CC_CVS_BASE=$(hg log -R $HGCVS -r 'tip' --template '{node}') CC_CVS_BASE=$(grep $CC_CVS_BASE $OUTPUT/.hg/shamap | cut -d' ' -f2) MC_CVS_BASE=$(hg log -R $HGCVS -r 'gitnode(215f52d06f4260fdcca797eebd78266524ea3d2c)' --template '{node}') MC_CVS_BASE=$(grep $MC_CVS_BASE $OUTPUT/.hg/shamap | cut -d' ' -f2) # Okay, now we need to build the map of revisions. cat >$WORKDIR/convert-revmap.txt <<EOF e4f4569d451a5e0d12a6aa33ebd916f979dd8faa $CC_CVS_BASE # Thunderbird / Suite 7c0bfdcda6731e77303f3c47b01736aaa93d5534 d4b728dc9da418f8d5601ed6735e9a00ac963c4e, $CC_CVS_BASE # Calendar 9b2a99adc05e53cd4010de512f50118594756650 $MC_CVS_BASE # Mozilla graft point ee719a0502491fc663bda942dcfc52c0825938d3 78b3d6c649f71eff41fe3f486c6cc4f4b899fd35, $MC_EDITOR_IMPORT # Editor 8cdfed92867f885fda98664395236b7829947a1d 4b5da7e5d0680c6617ec743109e6efc88ca413da, e4e612fcae9d0e5181a5543ed17f705a83a3de71 # Chat EOF # Next, import mozilla-central revisions for rev in $MC_MORK_IMPORT $MC_EDITOR_IMPORT $MC_SMIME_IMPORT; do hg convert $MC $OUTPUT -r $rev --splicemap $WORKDIR/convert-revmap.txt \ --filemap $WORKDIR/convert-filemap.txt doneSome notes about all of the revision ids in the script. The splicemap requires the full 40-character SHA ids; anything less and the thing complains. I also need to specify the parents of the revisions that deleted the code for the mozilla-central import, so if you go hunting for those revisions and are surprised that they don't remove the code in question, that's why.
I mentioned complications about the merges earlier. The Mork and S/MIME import codes here moved files, so that what was db/mdb in mozilla-central became db/mork. There's no support for causing the generated splice to record these as a move, so I have to manually construct those renamings:
# We need to execute a few hg move commands due to renamings. pushd $OUTPUT hg update -r $(grep $MC_MORK_IMPORT .hg/shamap | cut -d' ' -f2) (hg -R $MC log -r "children($MC_MORK_IMPORT)" \ --template "{file_dels % 'hg mv {file} {sub(\"db/mdb\", \"db/mork\", file)}\n'}") | bash hg commit -m 'Pseudo-changeset to move Mork files' -d '2011-08-06 17:25:21 +0200' MC_MORK_IMPORT=$(hg log -r tip --template '{node}') hg update -r $(grep $MC_SMIME_IMPORT .hg/shamap | cut -d' ' -f2) (hg -R $MC log -r "children($MC_SMIME_IMPORT)" \ --template "{file_dels % 'hg mv {file} {sub(\"security/manager/ssl\", \"mailnews/mime\", file)}\n'}") | bash hg commit -m 'Pseudo-changeset to move S/MIME files' -d '2014-06-15 20:51:51 -0700' MC_SMIME_IMPORT=$(hg log -r tip --template '{node}') popd # Echo the new move commands to the changeset conversion map. cat >>$WORKDIR/convert-revmap.txt <<EOF 52efa9789800829c6f0ee6a005f83ed45a250396 abfd23d7c5042bc87502506c9f34c965fb9a09d1, $MC_MORK_IMPORT # Mork 50f5b5fc3f53c680dba4f237856e530e2097adfd 97253b3cca68f1c287eb5729647ba6f9a5dab08a, $MC_SMIME_IMPORT # S/MIME EOFNow that we have all of the graft points defined, and all of the external code ready, we can pull comm-central and do the conversion. That's not quite it, though—when we graft the S/MIME history to the original mozilla-central history, we have a small segment of abandoned converted history. A call to hg strip removes that.
# Now, import comm-central revisions that we need hg convert $CC $OUTPUT --splicemap $WORKDIR/convert-revmap.txt hg strip 2f69e0a3a05a
[1] I left out one of the graft points because I just didn't want to deal with it. I'll leave it as an exercise to the reader to figure out which one it was. Hint: it's the only one I didn't know about before I searched for the archive points [2].
[2] Since I wasn't sure I knew all of the graft points, I decided to try to comb through all of the changesets to figure out who imported code. It turns out that hg log -r 'adds("**")' narrows it down nicely (1667 changesets to look at instead of 17547), and using the {file_adds} template helps winnow it down more easily.
Philipp Kewisch: Monitor all http(s) network requests using the Mozilla Platform
In an xpcshell test, I recently needed a way to monitor all network requests and access both request and response data so I can save them for later use. This required a little bit of digging in Mozilla’s devtools code so I thought I’d write a short blog post about it.
This code will be used in a testcase that ensures that calendar providers in Lightning function properly. In the case of the CalDAV provider, we would need to access a real server for testing. We can’t just set up a few servers and use them for testing, it would end in an unreasonable amount of server maintenance. Given non-local connections are not allowed when running the tests on the Mozilla build infrastructure, it wouldn’t work anyway. The solution is to create a fakeserver, that is able to replay the requests in the same way. Instead of manually making the requests and figuring out how the server replies, we can use this code to quickly collect all the requests we need.
Without further delay, here is the code you have been waiting for:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Show hidden characters
TracedRequest.js
hosted with ❤ by GitHub
Ludovic Hirlimann: Tips on organizing a pgp key signing party
Over the years I’ve organized or tried to organize pgp key signing parties every time I go somewhere. I the last year I’ve organized 3 that were successful (eg with more then 10 attendees).
1. Have a venueI’ve tried a bunch of times to have people show up at the hotel I was staying in the morning - that doesn’t work. Having catering at the venues is even better, it will encourage people to come from far away (or long distance commute). Try to show the path in the venues with signs (paper with PGP key signing party and arrows help).
2. Date and timeMeeting in the evening after work works better ( after 18 or 18:30 works better).
Let people know how long it will take (count 1 hour/per 30 participants).
3. Make people sign upThat makes people think twice before saying they will attend. It’s also an easy way for you to know how much beer/cola/ etc.. you’ll need to provide if you cater food.
I’ve been using eventbrite to manage attendance at my last three meeting it let’s me :
- know who is coming
- Mass mail participants
- have them have a calendar reminder
For such a party you need people to attend so you need to reach out.
I always start by a search on biglumber.com to find who are the people using gpg registered on that site for the area I’m visiting (see below on what I send).
Then I look for local linux users groups / *BSD groups and send an announcement to them with :
- date
- venue
- link to eventbrite and why I use it
- ask them to forward (they know the area better than you)
- I also use lanyrd and twitter but I’m not convinced that it works.
for my last announcement it looked like this :
Subject: GnuPG / PGP key signing party September 26 2014 Content-Type: multipart/signed; micalg=pgp-sha256; protocol="application/pgp-signature"; boundary="t01Mpe56TgLc7mgHKVMajjwkqQdw8XvI4" This is an OpenPGP/MIME signed message (RFC 4880 and 3156) --t01Mpe56TgLc7mgHKVMajjwkqQdw8XvI4 Content-Type: text/plain; charset=utf-8 Content-Transfer-Encoding: quoted-printable Hello my name is ludovic, I'm a sysadmins at mozilla working remote from europe. I've been involved with Thunderbird a lot (and still am). I'm organizing a pgp Key signing party in the Mozilla san francisco office on September the 26th 2014 from 6PM to 8PM. For security and assurances reasons I need to count how many people will attend. I'v setup a eventbrite for that at https://www.eventbrite.com/e/gnupg-pgp-key-signing-party-making-the-web-o= f-trust-stronger-tickets-12867542165 (please take one ticket if you think about attending - If you change you mind cancel so more people can come). I will use the eventbrite tool to send reminders and I will try to make a list with keys and fingerprint before the event to make things more manageable (but I don't promise). for those using lanyrd you will be able to use http://lanyrd.com/ccckzw. Ludovic ps sent to buug.org,nblug.org end penlug.org - please feel free to post where appropriate ( the more the meerier, the stronger the web of trust).= ps2 I have contacted people listed on biglumber to have more gpg related people show up. --=20 [:Usul] MOC Team at Mozilla QA Lead fof Thunderbird http://sietch-tabr.tumblr.com/ - http://weusepgp.info/ 5. Make it easy to attendAs noted above making a list of participants to hand out helps a lot (I’ve used http://www.phildev.net/pius/ and my own stuff to make a list). It make it easier for you, for attendees. Tell people what they need to bring (IDs, pen, printed fingerprints if you don’t provide a list).
6. Send remindersSend people reminder and let them know how many people intend to show up. It boosts audience.
Ludovic Hirlimann: Gnupg / PGP key signing party in mozilla's San francisco space
I’m organizing a pgp Keysigning party in the Mozilla san francisco office on September the 26th 2014 from 6PM to 8PM.
For security and assurances reasons I need to count how many people will attend. I’ve setup a eventbrite for that at https://www.eventbrite.com/e/gnupg-pgp-key-signing-party-making-the-web-of-trust-stronger-tickets-12867542165 (please take one ticket if you think about attending - If you change you mind cancel so more people can come).
I will use the eventbrite tool to send reminders and I will try to make a list with keys and fingerprint before the event to make things more manageable (but I don’t promise).
For those using lanyrd you will be able to use http://lanyrd.com/ccckzw.(Please tweet the event to get more people in).
Joshua Cranmer: Why email is hard, part 7: email security and trust
At a technical level, S/MIME and PGP (or at least PGP/MIME) use cryptography essentially identically. Yet the two are treated as radically different models of email security because they diverge on the most important question of public key cryptography: how do you trust the identity of a public key? Trust is critical, as it is the only way to stop an active, man-in-the-middle (MITM) attack. MITM attacks are actually easier to pull off in email, since all email messages effectively have to pass through both the sender's and the recipients' email servers [1], allowing attackers to be able to pull off permanent, long-lasting MITM attacks [2].
S/MIME uses the same trust model that SSL uses, based on X.509 certificates and certificate authorities. X.509 certificates effectively work by providing a certificate that says who you are which is signed by another authority. In the original concept (as you might guess from the name "X.509"), the trusted authority was your telecom provider, and the certificates were furthermore intended to be a part of the global X.500 directory—a natural extension of the OSI internet model. The OSI model of the internet never gained traction, and the trusted telecom providers were replaced with trusted root CAs.
PGP, by contrast, uses a trust model that's generally known as the Web of Trust. Every user has a PGP key (containing their identity and their public key), and users can sign others' public keys. Trust generally flows from these signatures: if you trust a user, you know the keys that they sign are correct. The name "Web of Trust" comes from the vision that trust flows along the paths of signatures, building a tight web of trust.
And now for the controversial part of the post, the comparisons and critiques of these trust models. A disclaimer: I am not a security expert, although I am a programmer who revels in dreaming up arcane edge cases. I also don't use PGP at all, and use S/MIME to a very limited extent for some Mozilla work [3], although I did try a few abortive attempts to dogfood it in the past. I've attempted to replace personal experience with comprehensive research [4], but most existing critiques and comparisons of these two trust models are about 10-15 years old and predate several changes to CA certificate practices.
A basic tenet of development that I have found is that the average user is fairly ignorant. At the same time, a lot of the defense of trust models, both CAs and Web of Trust, tends to hinge on configurability. How many people, for example, know how to add or remove a CA root from Firefox, Windows, or Android? Even among the subgroup of Mozilla developers, I suspect the number of people who know how to do so are rather few. Or in the case of PGP, how many people know how to change the maximum path length? Or even understand the security implications of doing so?
Seen in the light of ignorant users, the Web of Trust is a UX disaster. Its entire security model is predicated on having users precisely specify how much they trust other people to trust others (ultimate, full, marginal, none, unknown) and also on having them continually do out-of-band verification procedures and publicly reporting those steps. In 1998, a seminal paper on the usability of a GUI for PGP encryption came to the conclusion that the UI was effectively unusable for users, to the point that only a third of the users were able to send an encrypted email (and even then, only with significant help from the test administrators), and a quarter managed to publicly announce their private keys at some point, which is pretty much the worst thing you can do. They also noted that the complex trust UI was never used by participants, although the failure of many users to get that far makes generalization dangerous [5]. While newer versions of security UI have undoubtedly fixed many of the original issues found (in no small part due to the paper, one of the first to argue that usability is integral, not orthogonal, to security), I have yet to find an actual study on the usability of the trust model itself.
The Web of Trust has other faults. The notion of "marginal" trust it turns out is rather broken: if you marginally trust a user who has two keys who both signed another person's key, that's the same as fully trusting a user with one key who signed that key. There are several proposals for different trust formulas [6], but none of them have caught on in practice to my knowledge.
A hidden fault is associated with its manner of presentation: in sharp contrast to CAs, the Web of Trust appears to not delegate trust, but any practical widespread deployment needs to solve the problem of contacting people who have had no prior contact. Combined with the need to bootstrap new users, this implies that there needs to be some keys that have signed a lot of other keys that are essentially default-trusted—in other words, a CA, a fact sometimes lost on advocates of the Web of Trust.
That said, a valid point in favor of the Web of Trust is that it more easily allows people to distrust CAs if they wish to. While I'm skeptical of its utility to a broader audience, the ability to do so for is crucial for a not-insignificant portion of the population, and it's important enough to be explicitly called out.
X.509 certificates are most commonly discussed in the context of SSL/TLS connections, so I'll discuss them in that context as well, as the implications for S/MIME are mostly the same. Almost all criticism of this trust model essentially boils down to a single complaint: certificate authorities aren't trustworthy. A historical criticism is that the addition of CAs to the main root trust stores was ad-hoc. Since then, however, the main oligopoly of these root stores (Microsoft, Apple, Google, and Mozilla) have made their policies public and clear [7]. The introduction of the CA/Browser Forum in 2005, with a collection of major CAs and the major browsers as members, and several [8] helps in articulating common policies. These policies, simplified immensely, boil down to:
- You must verify information (depending on certificate type). This information must be relatively recent.
- You must not use weak algorithms in your certificates (e.g., no MD5).
- You must not make certificates that are valid for too long.
- You must maintain revocation checking services.
- You must have fairly stringent physical and digital security practices and intrusion detection mechanisms.
- You must be [externally] audited every year that you follow the above rules.
- If you screw up, we can kick you out.
I'm not going to claim that this is necessarily the best policy or even that any policy can feasibly stop intrusions from happening. But it's a policy, so CAs must abide by some set of rules.
Another CA criticism is the fear that they may be suborned by national government spy agencies. I find this claim underwhelming, considering that the number of certificates acquired by intrusions that were used in the wild is larger than the number of certificates acquired by national governments that were used in the wild: 1 and 0, respectively. Yet no one complains about the untrustworthiness of CAs due to their ability to be hacked by outsiders. Another attack is that CAs are controlled by profit-seeking corporations, which misses the point because the business of CAs is not selling certificates but selling their access to the root databases. As we will see shortly, jeopardizing that access is a great way for a CA to go out of business.
To understand issues involving CAs in greater detail, there are two CAs that are particularly useful to look at. The first is CACert. CACert is favored by many by its attempt to handle X.509 certificates in a Web of Trust model, so invariably every public discussion about CACert ends up devolving into an attack on other CAs for their perceived capture by national governments or corporate interests. Yet what many of the proponents for inclusion of CACert miss (or dismiss) is the fact that CACert actually failed the required audit, and it is unlikely to ever pass an audit. This shows a central failure of both CAs and Web of Trust: different people have different definitions of "trust," and in the case of CACert, some people are favoring a subjective definition (I trust their owners because they're not evil) when an objective definition fails (in this case, that the root signing key is securely kept).
The other CA of note here is DigiNotar. In July 2011, some hackers managed to acquire a few fraudulent certificates by hacking into DigiNotar's systems. By late August, people had become aware of these certificates being used in practice [9] to intercept communications, mostly in Iran. The use appears to have been caught after Chromium updates failed due to invalid certificate fingerprints. After it became clear that the fraudulent certificates were not limited to a single fake Google certificate, and that DigiNotar had failed to notify potentially affected companies of its breach, DigiNotar was swiftly removed from all of the trust databases. It ended up declaring bankruptcy within two weeks.
DigiNotar indicates several things. One, SSL MITM attacks are not theoretical (I have seen at least two or three security experts advising pre-DigiNotar that SSL MITM attacks are "theoretical" and therefore the wrong target for security mechanisms). Two, keeping the trust of browsers is necessary for commercial operation of CAs. Three, the notion that a CA is "too big to fail" is false: DigiNotar played an important role in the Dutch community as a major CA and the operator of Staat der Nederlanden. Yet when DigiNotar screwed up and lost its trust, it was swiftly kicked out despite this role. I suspect that even Verisign could be kicked out if it manages to screw up badly enough.
This isn't to say that the CA model isn't problematic. But the source of its problems is that delegating trust isn't a feasible model in the first place, a problem that it shares with the Web of Trust as well. Different notions of what "trust" actually means and the uncertainty that gets introduced as chains of trust get longer both make delegating trust weak to both social engineering and technical engineering attacks. There appears to be an increasing consensus that the best way forward is some variant of key pinning, much akin to how SSH works: once you know someone's public key, you complain if that public key appears to change, even if it appears to be "trusted." This does leave people open to attacks on first use, and the question of what to do when you need to legitimately re-key is not easy to solve.
In short, both CAs and the Web of Trust have issues. Whether or not you should prefer S/MIME or PGP ultimately comes down to the very conscious question of how you want to deal with trust—a question without a clear, obvious answer. If I appear to be painting CAs and S/MIME in a positive light and the Web of Trust and PGP in a negative one in this post, it is more because I am trying to focus on the positions less commonly taken to balance perspective on the internet. In my next post, I'll round out the discussion on email security by explaining why email security has seen poor uptake and answering the question as to which email security protocol is most popular. The answer may surprise you!
[1] Strictly speaking, you can bypass the sender's SMTP server. In practice, this is considered a hole in the SMTP system that email providers are trying to plug.
[2] I've had 13 different connections to the internet in the same time as I've had my main email address, not counting all the public wifis that I have used. Whereas an attacker would find it extraordinarily difficult to intercept all of my SSH sessions for a MITM attack, intercepting all of my email sessions is clearly far easier if the attacker were my email provider.
[3] Before you read too much into this personal choice of S/MIME over PGP, it's entirely motivated by a simple concern: S/MIME is built into Thunderbird; PGP is not. As someone who does a lot of Thunderbird development work that could easily break the Enigmail extension locally, needing to use an extension would be disruptive to workflow.
[4] This is not to say that I don't heavily research many of my other posts, but I did go so far for this one as to actually start going through a lot of published journals in an attempt to find information.
[5] It's questionable how well the usability of a trust model UI can be measured in a lab setting, since the observer effect is particularly strong for all metrics of trust.
[6] The web of trust makes a nice graph, and graphs invite lots of interesting mathematical metrics. I've always been partial to eigenvectors of the graph, myself.
[7] Mozilla's policy for addition to NSS is basically the standard policy adopted by all open-source Linux or BSD distributions, seeing as OpenSSL never attempted to produce a root database.
[8] It looks to me that it's the browsers who are more in charge in this forum than the CAs.
[9] To my knowledge, this is the first—and so far only—attempt to actively MITM an SSL connection.
Ludovic Hirlimann: Thunderbird 31 coming soon to you and needs testing love
We just released the second beta of Thunderbird 31. Please help us improve Thunderbird quality by uncovering bugs now in Thunderbird 31 beta so that developers have time to fix them.
There are two ways you can help
- Use Thunderbird 31 beta in your daily activities. For problems that you find, file a bug report that blocks our tracking bug 1008543.
- Use Thunderbird 31 beta to do formal testing. Use the moztrap testing system to tests : choose run test - find the Thunderbird product and choose 31 test run.
Visit https://etherpad.mozilla.org/tbird31testing for additional information, and to post your testing questions and results.
Thanks for contributing and helping!
Ludo for the QA team
Updated links
Joshua Cranmer: Why email is hard, part 6: today's email security
Email security is a rather wide-ranging topic, and one that I've wanted to cover for some time, well before several recent events that have made it come up in the wider public knowledge. There is no way I can hope to cover it in a single post (I think it would outpace even the length of my internationalization discussion), and there are definitely parts for which I am underqualified, as I am by no means an expert in cryptography. Instead, I will be discussing this over the course of several posts of which this is but the first; to ease up on the amount of background explanation, I will assume passing familiarity with cryptographic concepts like public keys, hash functions, as well as knowing what SSL and SSH are (though not necessarily how they work). If you don't have that knowledge, ask Wikipedia.
Before discussing how email security works, it is first necessary to ask what email security actually means. Unfortunately, the layman's interpretation is likely going to differ from the actual precise definition. Security is often treated by laymen as a boolean interpretation: something is either secure or insecure. The most prevalent model of security to people is SSL connections: these allow the establishment of a communication channel whose contents are secret to outside observers while also guaranteeing to the client the authenticity of the server. The server often then gets authenticity of the client via a more normal authentication scheme (i.e., the client sends a username and password). Thus there is, at the end, a channel that has both secrecy and authenticity [1]: channels with both of these are considered secure and channels without these are considered insecure [2].
In email, the situation becomes more difficult. Whereas an SSL connection is between a client and a server, the architecture of email is such that email providers must be considered as distinct entities from end users. In addition, messages can be sent from one person to multiple parties. Thus secure email is a more complex undertaking than just porting relevant details of SSL. There are two major cryptographic implementations of secure email [3]: S/MIME and PGP. In terms of implementation, they are basically the same [4], although PGP has an extra mode which wraps general ASCII (known as "ASCII-armor"), which I have been led to believe is less recommended these days. Since I know the S/MIME specifications better, I'll refer specifically to how S/MIME works.
S/MIME defines two main MIME types: multipart/signed, which contains the message text as a subpart followed by data indicating the cryptographic signature, and application/pkcs7-mime, which contains an encrypted MIME part. The important things to note about this delineation are that only the body data is encrypted [5], that it's theoretically possible to encrypt only part of a message's body, and that the signing and encryption constitute different steps. These factors combine to make for a potentially infuriating UI setup.
How does S/MIME tackle the challenges of encrypting email? First, rather than encrypting using recipients' public keys, the message is encrypted with a symmetric key. This symmetric key is then encrypted with each of the recipients' keys and then attached to the message. Second, by only signing or encrypting the body of the message, the transit headers are kept intact for the mail system to retain its ability to route, process, and deliver the message. The body is supposed to be prepared in the "safest" form before transit to avoid intermediate routers munging the contents. Finally, to actually ascertain what the recipients' public keys are, clients typically passively pull the information from signed emails. LDAP, unsurprisingly, contains an entry for a user's public key certificate, which could be useful in large enterprise deployments. There is also work ongoing right now to publish keys via DNS and DANE.
I mentioned before that S/MIME's use can present some interesting UI design decisions. I ended up actually testing some common email clients on how they handled S/MIME messages: Thunderbird, Apple Mail, Outlook [6], and Evolution. In my attempts to create a surreptitious signed part to confuse the UI, Outlook decided that the message had no body at all, and Thunderbird decided to ignore all indication of the existence of said part. Apple Mail managed to claim the message was signed in one of these scenarios, and Evolution took the cake by always agreeing that the message was signed [7]. It didn't even bother questioning the signature if the certificate's identity disagreed with the easily-spoofable From address. I was actually surprised by how well people did in my tests—I expected far more confusion among clients, particularly since the will to maintain S/MIME has clearly been relatively low, judging by poor support for "new" features such as triple-wrapping or header protection.
Another fault of S/MIME's design is that it makes the mistaken belief that composing a signing step and an encryption step is equivalent in strength to a simultaneous sign-and-encrypt. Another page describes this in far better detail than I have room to; note that this flaw is fixed via triple-wrapping (which has relatively poor support). This creates yet more UI burden into how to adequately describe in UI all the various minutiae in differing security guarantees. Considering that users already have a hard time even understanding that just because a message says it's from example@isp.invalid doesn't actually mean it's from example@isp.invalid, trying to develop UI that both adequately expresses the security issues and is understandable to end-users is an extreme challenge.
What we have in S/MIME (and PGP) is a system that allows for strong guarantees, if certain conditions are met, yet is also vulnerable to breaches of security if the message handling subsystems are poorly designed. Hopefully this is a sufficient guide to the technical impacts of secure email in the email world. My next post will discuss the most critical component of secure email: the trust model. After that, I will discuss why secure email has seen poor uptake and other relevant concerns on the future of email security.
[1] This is a bit of a lie: a channel that does secrecy and authentication at different times isn't as secure as one that does them at the same time.
[2] It is worth noting that authenticity is, in many respects, necessary to achieve secrecy.
[3] This, too, is a bit of a lie. More on this in a subsequent post.
[4] I'm very aware that S/MIME and PGP use radically different trust models. Trust models will be covered later.
[5] S/MIME 3.0 did add a provision stating that if the signed/encrypted part is a message/rfc822 part, the headers of that part should override the outer message's headers. However, I am not aware of a major email client that actually handles these kind of messages gracefully.
[6] Actually, I tested Windows Live Mail instead of Outlook, but given the presence of an official MIME-to-Microsoft's-internal-message-format document which seems to agree with what Windows Live Mail was doing, I figure their output would be identical.
[7] On a more careful examination after the fact, it appears that Evolution may have tried to indicate signedness on a part-by-part basis, but the UI was sufficiently confusing that ordinary users are going to be easily confused.
Ludovic Hirlimann: The next major release of Thunderbird is around the corner and needs some love
We just released the first beta of Thunderbird 30. There will be two betas for 30 and probably 2 or more for 31. We need to start uncovering bugs nows so that developers have time to fix things.
Now is the time to get the betas and use them as you do with the current release and file bugs. Makes these bugs block our tracking bug : 1008543.
For the next beta we will need more people to do formal testing - we will use moztrap and eventbrite to track this. The more participants to this (and other during the 31 beta period), the higher the quality. Follow this blog or subscribe to the Thunderbird-tester mailing list if you wish to make 31 a great release.
Ludo for the QA team
Andrew Sutherland: webpd: a Polymer-based web UI for the beets music library manager
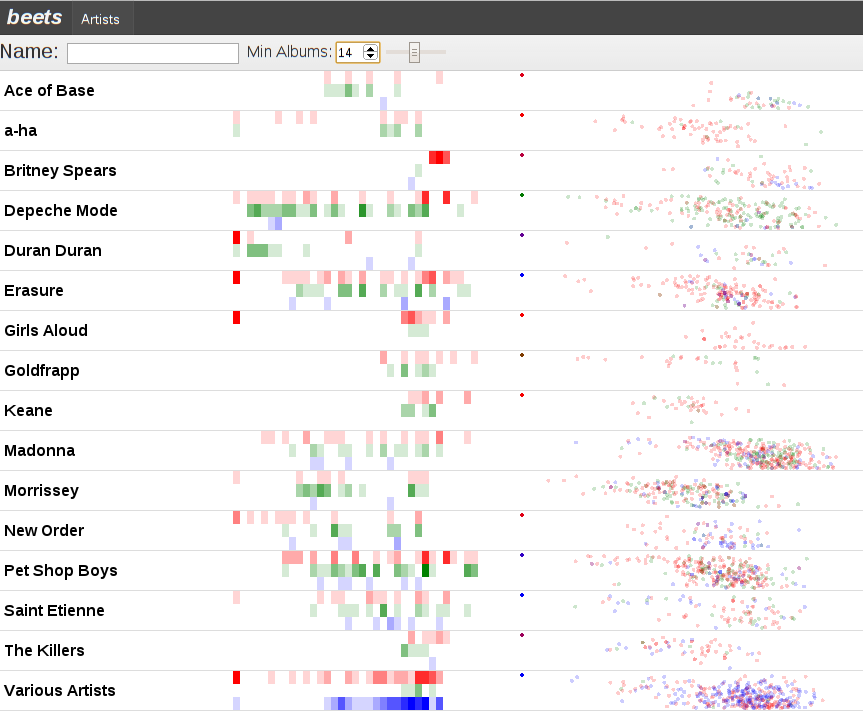
beets is the extensible music database tool every programmer with a music collection has dreamed of writing. At its simplest it’s a clever tagger that can normalize your music against the MusicBrainz database and then store the results in a searchable SQLite database. But with plugins it can fetch album art, use the Discogs music database for tagging too, calculate ReplayGain values for all your music, integrate meta-data from The Echo Nest, etc. It even has a Music Player Daemon server-mode (bpd) and a simple HTML interface (web) that lets you search for tracks and play them in your browse using the HTML5 audio tag.
I’ve tried a lot of music players through the years (alphabetically: amarok, banshee, exaile, quodlibet, rhythmbox). They all are great music players and (at least!) satisfy the traditional Artist/Album/Track hierarchy use-case, but when you exceed 20,000 tracks and you have a lot of compilation cd’s, that frequently ends up not being enough. Extending them usually turned out to be too hard / not fun enough, although sometimes it was just a question of time and seeking greener pastures.
But enough context; if you’re reading my blog you probably are on board with the web platform being the greatest platform ever. The notable bits of the implementation are:
- Server-wise, it’s a mash-up of beets’ MPD-alike plugin bpd and its web plugin. Rather than needing to speak the MPD protocol over TCP to get your server to play music, you can just hit it with an HTTP POST and it will enqueue and play the song. Server-sent events/EventSource are used to let the web UI hypothetically update as things happen on the server. Right now the client can indeed tell the server to play a song and hear an update via the EventSource channel, but there’s almost certainly a resource leak on the server-side and there’s a lot more web/bpd interlinking required to get it reliable. (Python’s Flask is neat, but I’m not yet clear on how to properly manage the life-cycle of a long-lived request that only dies when the connection dies since I’m seeing the appcontext get torn down even before the generator starts running.)
- The client is implemented in Polymer on top of some simple backbone.js collections that build on the existing logic from the beets web plugin.
- The artist list uses the polymer-virtual-list element which is important if you’re going to be scrolling through a ton of artists. The implementation is page-based; you tell it how many pages you want and how many items are on each page. As you scroll it fires events that compel you to generate the appropriate page. It’s an interesting implementation:
- Pages are allowed to be variable height and therefore their contents are too, although a fixedHeight mode is also supported.
- In variable-height mode, scroll offsets are translated to page positions by guessing the page based on the height of the first page and then walking up/down from there based on cached page-sizes until the right page size is found. If there is missing information because the user managed to trigger a huge jump, extrapolation is performed based on the average item size from the first page.
- Any changes to the contents of the list regrettably require discarding all existing pages/bindings. At this time there is no way to indicate a splice at a certain point that should simply result in a displacement of the existing items.
- Albums are loaded in batches from the server and artists dynamically derived from them. Although this would allow for the UI to update as things are retrieved, the virtual-list invalidation issue concerned me enough to have the artist-list defer initialization until all albums are loaded. On my machine a couple thousand albums load pretty quickly, so this isn’t a huge deal.
- There’s filtering by artist name and number of albums in the database by that artist built on backbone-filtered-collection. The latter one is important to me because scrolling through hundreds of artists where I might only own one cd or not even one whole cd is annoying. (Although the latter is somewhat addressed currently by only using the albumartist for the artist generation so various artists compilations don’t clutter things up.)
- If you click on an artist it plays the first track (numerically) from the first album (alphabetically) associated with the artist. This does limit the songs you can listen to somewhat…
- visualizations are done using d3.js; one svg per visualization
- The artist list uses the polymer-virtual-list element which is important if you’re going to be scrolling through a ton of artists. The implementation is page-based; you tell it how many pages you want and how many items are on each page. As you scroll it fires events that compel you to generate the appropriate page. It’s an interesting implementation:

“What’s with all those tastefully chosen colors?” is what you are probably asking yourself. The answer? Two things!
- A visualization of albums/releases in the database by time, heat-map style.
- We bin all of the albums that beets knows about by year. In this case we assume that 1980 is the first interesting year and so put 1979 and everything before it (including albums without a year) in the very first bin on the left. The current year is the rightmost bucket.
- We vertically divide the albums into “albums” (red), “singles” (green), and “compilations” (blue). This is accomplished by taking the MusicBrainz Release Group / Types and mapping them down to our smaller space.
- The more albums in a bin, the stronger the color.
- A scatter-plot using the echo nest‘s acoustic attributes for the tracks where:
- the x-axis is “danceability”. Things to the left are less danceable. Things to the right are more danceable.
- the y-axis is “valence” which they define as “the musical positiveness conveyed by a track”. Things near the top are sadder, things near the bottom are happier.
- the colors are based on the type of album the track is from. The idea was that singles tend to have remixes on them, so it’s interesting if we always see a big cluster of green remixes to the right.
- tracks without the relevant data all end up in the upper-left corner. There are a lot of these. The echo nest is extremely generous in allowing non-commercial use of their API, but they limit you to 20 requests per minute and at this point the beets echonest plugin needs to upload (transcoded) versions of all my tracks since my music collection is apparently more esoteric than what the servers already have fingerprints for.
Together these visualizations let us infer:
- Madonna is more dancey than Morrissey! Shocking, right?
- I bought the Morrissey singles box sets. And I got ripped off because there’s a distinct lack of green dots over on the right side.
Code is currently in the webpd branch of my beets fork although I should probably try and split it out into a separate repo. You need to enable the webpd plugin like you would any other plugin for it to work. There’s still a lot lot lot more work to be done for it to be usable, but I think it’s neat already. It definitely works in Firefox and Chrome.