
Mozilla Announces Call for Entries for the 2nd Annual Rise25 Awards in Dublin, Ireland
Haven’t filled out the nomination form yet? You’re in luck. We are extending the deadline for nominations for 2024’s Rise25 cohort until 5PM PT Friday, April 12th. You can nominate someone you know who is making an impact with AI (or yourself) below:
www.mozilla.org/rise25/nominate/
On the heels of Mozilla’s Rise25 Awards in Berlin last year, we’re excited to announce that we’ll be returning once again with a special celebration that will take place in Dublin, Ireland later this year.
The 2nd Annual Rise25 Awards will feature familiar categories, but with an emphasis on trustworthy AI. We will be honoring 25 people who are leading that next wave of AI — who are using philanthropy, collective power, and the principles of open source to make sure the future of AI is responsible, trustworthy, inclusive and centered around human dignity.
2023 was indeed the year of AI, and as more people adopt it, we know it is a technology that will continue to impact our culture and society, act as a catalyst for innovation and creation, and be a medium to engage people from all walks of life in conversations thanks to its growing ubiquity in our everyday lives.
We know we cannot do this alone: At Mozilla, we believe the most groundbreaking innovations emerge when people from diverse backgrounds unite to collaborate and openly trade ideas.
So if you know someone who you think should be celebrated, we want to hear from you!
Five winners from each of the five categories below will be selected to make up our 2024 Rise25 cohort:
Advocates – Guiding AI towards a responsible future
These are the policymakers, activists, and thinkers ensuring AI is developed ethically, inclusively, and transparently. This category also includes those who are adept at translating complex AI concepts for the broader public — including journalists, content creators, and cultural commentators. They champion digital rights and accessible AI, striving to make AI a force for societal good.
Builders – Developing AI through ethical innovation
They are the architects of trustworthy AI, including engineers and data scientists dedicated to developing AI’s open-source language infrastructure. They focus on technical proficiency and responsible and ethical construction. Their work ensures AI is secure, accessible, and reliable, aiming to create tools that empower and advance society.
Artists – Reimagining AI’s creative potential
They transcend traditional AI applications, like synthesizing visuals or using large language models. Their projects, whether interactive websites, films, or digital media, challenge our perceptions and demonstrate how AI can amplify and empower human creativity. Their work provokes thought and offers fresh perspectives on the intersection of AI and art.
Entrepreneurs – Fueling AI’s evolution with visionary ventures
These daring individuals are transforming imaginative ideas into reality. They’re crafting businesses and solutions with AI to meet societal needs, improve everyday life and forge new technological paths. They embody innovation, steering startups and projects with a commitment to ethical standards, inclusiveness and enhancing human welfare through technology.
Change Agents – Cultivating inclusive AI
They are challengers that lead the way in diversifying AI, bringing varied community voices into tech. They focus on inclusivity in AI development, ensuring technology serves and represents everyone, especially those historically excluded from the tech narrative. They are community leaders, corporate leaders, activists and outside-the-box thinkers finding ways to amplify the impacts of AI for marginalized communities. Their work fosters an AI environment of equality and empowerment.
This year’s awards build upon the success of last year’s programming and community event in Berlin, which brought to life what a future trustworthy Internet could look like. Last year’s event crowned trailblazers and visionaries across five distinct categories: Builders, Activists, Artists, Creators, and Advocates. (Psst! Stay tuned as we unveil their inspiring stories in a video series airing across Mozilla channels throughout the year, leading up to the 2nd Annual Rise25 Awards.)
So join us as we honor the innovators, advocates, entrepreneurs, and communities who are working to build a happier, healthier web. Click here to submit your nomination today.
The post Mozilla Announces Call for Entries for the 2nd Annual Rise25 Awards in Dublin, Ireland appeared first on The Mozilla Blog.
How the U.S. Government is leading by example on artificial intelligence - Open Policy & Advocacy - Mozilla
Readouts from the Columbia Convening on Openness and AI
On February 29, Mozilla and the Columbia Institute of Global Politics brought together over 40 leading scholars and practitioners working on openness and AI. These individuals — spanning prominent open source AI startups and companies, non-profit AI labs, and civil society organizations — focused on exploring what “open” should mean in the AI era. We previously wrote about the convening, why it was important, and who we brought together.
Today, we are publishing two readouts from the convening.The first is a technical memorandum that outlines three different approaches to openness in AI, and highlights different components and spectrums of openness. It includes an extensive appendix that outlines key components in the AI stack, and describes how more openness in each component can help advance system and societal goals. Finally, it outlines open questions that would be worthy of future exploration, digging deeper into the specifics of openness and AI. This memorandum will be helpful for technical leaders and practitioners who are shaping the future of AI, so that they can better incorporate principles of openness to make their own AI systems more effective for their goals and more beneficial for society.
The second is a policy memorandum that outlines how and why policymakers should support openness in AI. It outlines the societal benefits from openness in AI, provides a higher-level overview of how different parts of the AI stack contribute to different opportunities and risks, and lays out a series of recommendations about how policymakers can advance openness in AI. This memorandum will be helpful for policymakers, especially those who are grappling with the details of policy interventions related to openness in AI.
In the coming weeks, we will also be publishing a longer document that goes into greater detail about the dimensions of openness in AI. This will help advance our broader work with partners and allies to tackle complex and important topics around openness, competition, and accountability in AI. We will continue to keep mozilla.org/research/cc updated with materials stemming from the Columbia Convening on Openness and AI.
The post Readouts from the Columbia Convening on Openness and AI appeared first on The Mozilla Blog.
Mozilla Calls on Regulators to Support Open Source AI Models - ExtremeTech
Mozilla Patches Firefox Zero-Days Exploited at Pwn2Own - SecurityWeek
Mozilla fixes $100,000 Firefox zero-days following two-day hackathon - The Register
6 takeaways from The Washington Post Futurist Tech Summit in D.C.
A full conglomerate including journalists from The Washington Post, U.S. policymakers and influential business leaders gathered for a day of engaging discussions about technology March 21 in the nation’s capital.
Mozilla sponsored “The Futurist Summit: The New Age of Tech,” an event focused on addressing the wide range of promise and risks associated with emerging technologies — the largest of them being Artificial Intelligence (AI). It featured interviews moderated by journalists from The Post, as well as interactive sessions about tech for audience members in attendance at the paper’s office in Washington D.C.
Missed the event? Here are six takeaways from it that you should know about:
1. How OpenAI is preparing for the election.
The 2024 U.S. presidential election is one of the biggest topics of discussion involving the emergence and dangers of AI this year. It’s no secret that AI has incredible power to create, influence and manipulate voters with misinformation and fake media content (video, photos, audio) that can unfairly sway voters.
OpenAI, one of the biggest AI organizations, stressed an importance to provide transparency for its users to ensure their tools aren’t being used in those negative ways to mislead the public.
“It’s four billion people voting, and that is really unprecedented, and we’re very, very cognizant of that,” OpenAI VP of Global Affairs Anna Makanju said. “And obviously, it’s one of the things that we work — to ensure that our tools are not used to deceive people and to mislead people.”
Makanju reiterated that AI concerns with the election is a very large scale, and OpenAI is focused on engaging with companies to hammer down transparency in the 2024 race.
“This is like a whole of society issue,” Makanju said. “So that’s why we have engaged with other companies in this space as well. As you may have seen in the Munich Security Conference, we announced the Tech Accord, where we’re going to collaborate with social media companies and other companies that generate AI content, because there’s the issue of generation of AI content and the issue of distribution, and they’re quite different. So, for us, we really focus on things like transparency. … We of course have lots of teams investigating abuse of our systems or circumvention of the use case guidelines that are intended to prevent this kind of work. So, there are many teams at OpenAI working to ensure that these tools aren’t used for election interference.”
And OpenAI will be in the spotlight even more as the election inches closer. According to a report from Business Insider, OpenAI is preparing to launch GPT-5 this summer, which will reportedly eclipse the abilities of the ChatGPT chatbot.
 The futurist summit focused on the wide range of promise and risks associated with emerging technologies
The futurist summit focused on the wide range of promise and risks associated with emerging technologies
2. Policymakers address the potential TikTok ban.
The House overwhelmingly voted 352-65 on March 13 to pass a measure that gives ByteDance, the parent company of TikTok, a decision: Sell the social media platform or face a nationwide ban on all U.S. devices.
One of the top lawmakers on the Senate Intelligence Committee, Sen. Mark Warner (D-Va.), addressed the national security concerns around TikTok on a panel moderated by political reporter Leigh Ann Caldwell alongside Sen. Todd Young (R-Ind.).
“There is something uniquely challenging about TikTok because ultimately if this information is turned over to the Chinese espionage services that could be then potentially used for nefarious purposes, that’s not a good thing for America’s long-term national security interests,” Werner said. “End of the day, all we want is it could be an American company, it could be a British company, it could be a Brazilian company. It just needs not to be from one of the nation states, China being one of the four, that are actually named in American law as adversarial nations.”
Young chimed in shortly after Warner: “Though I have not authored a bill on this particular topic, I’ve been deeply involved, for several years running now, in this effort to harden ourselves against a country, China, that has weaponized our economic interdependence in various ways.”
The fate of the measure now heads to the Senate, which is not scheduled to vote on it soon.
3. Deep Media AI is fighting against fake media content.
AI to fight against AI? Yes, it’s possible!
AI being able to alter how we perceive reality through deepfakes — in other words, synthetic media — is another danger of the emerging technology. Deep Media AI founder Rijul Gupta is countering that AI problem with AI of his own.
In a video demonstration alongside tech columnist Geoffrey Fowler, Gupta showcased how Deep Media AI scans and detects deepfakes in photos, videos and audio files to combat the issue.
For example, Deep Media AI can determine if a photo is fake by looking at wrinkles, reflections and things humans typically don’t pay attention to. In the audio space, which Gupta described as “uniquely dangerous,” the technology analyzes the waves and patterns. It can detect video deepfakes by tracking motion of the face — how it moves, the shape and movement of lips — and changes in lighting.
A good sign: Audience members were asked to identify a deepfake between two video clips (one real, one AI generated by OpenAI) at the start of Gupta’s presentation. The majority of people in attendance guessed correctly. Even better: Deep Media AI detected it was fake and scored a 100/100 in its detection system. In other words, it got it right perfectly.
“Generative AI is going to be awesome; it’s going to make us all rich; it’s going to be great,” Gupta said. “But in order for that to happen, we need to make it safe. We’re part of that, but we need militaries and governments. We need buy-in from the generative AI companies. We need buy-in from the tech ecosystem. We need detectors. And we need journalists to tell us what’s real, and what’s fake from a trusted source, right? I think it’s possible. We’re here to help, but we’re not the only ones here. We’re hoping to provide solutions that people use.”
 VP of Global Policy at Mozilla, Linda Griffin, interviewed by The Washington Post’s Kathleen Koch.
VP of Global Policy at Mozilla, Linda Griffin, interviewed by The Washington Post’s Kathleen Koch.
4. Mozilla’s push for trustworthy AI
As we continue to shift towards a world with AI that’s helpful, it’s important we involve human beings in that process as much as possible. It’s concerning if companies are making AI while only thinking about profit and not the public. That hurts public trust and faith in big tech.
This work is urgent, and Mozilla has been delivering the trustworthy AI report — which had a 2020 status update in February — to aid in aligning with our vision of creating a healthy internet where openness, competition and accountability are the norms.
“We want to know what you think,” Mozilla VP of Global Policy Linda Griffin said. “We’re trying to map and guide where we think these conversations are. What is the point of AI unless more people can benefit from it more broadly? What is the point of this technology if it’s just in the hands of the handful of companies thinking about their bottom line?
“They do important and really interesting things with the technology; that’s great. But we need more; we need the public counterpoint. So, for us, trustworthy AI, it’s about accountability, transparency, and having humans in the loop thinking about people wanting to use these products and feeling safe and understanding that they have recourse if something goes wrong.”
5. AI’s ability to change rules in the NFL (yes!).
While the NFL is early in the process of incorporating AI into the game of football, the league has found ways to get the ball rolling (pun intended) on using its tools to make the game smarter and better.
One area is with health and safety, a major priority for the NFL. The league uses AI and machine learning tools on the field to grab predictive analysis to identify plays and body positions that most likely lead to players getting injured. Then, they can adjust rules and strategies accordingly, if they want.
For example, kickoffs. Concussions sustained on kickoffs dropped by 60 percent in the NFL last season, from 20 to eight. That is because kickoffs were returned less frequently after the league adjusted the rules governing kickoff returns during the previous offseason, so that a returner could signal for a fair catch no matter where the ball was kicked, and the ball would be placed on the 25-yard line. This change came after the NFL used AI tools to gather injury data on those plays.
“The insight to change that rule had come from a lot of the data we had collected with chips on the shoulder pads of our players of capturing data, using machine learning, and trying to figure out what is the safest way to play the game,” Brian Rolapp, Chief Media & Business Officer for the NFL, told media reporter Ben Strauss, “which led to an impact of rule change.”
While kickoff injuries have gone down, making this tweak to one of the most exciting plays in football is tough. So this year, the NFL is working on a compromise and exploring new ideas that can strike a balance to satisfy both safety and excitement. There will be a vote at league meetings this week in front of coaches, general managers and ownership about it.
6. Don’t forget about tech for accessibility.
With the new chapter of AI, the possibilities of investing and creating tools for those with disabilities is endless. For those who are blind, have low vision or have trouble hearing, AI offers an entire new slate of capabilities.
Apple has been one of the companies at the forefront creating features for those with disabilities that use their products. For example, on iPhones, Apple has implemented live captions, sound recognition and voice control on devices to assist.
Sarah Herrlinger, Senior Director of Global Accessibility Policy & Initiatives at Apple, gave insight into how the tech giant decides what features to add and which ones to update. In doing so, she delivered one of the best talking points of the day.
“I think the key to that is really engagement with the communities,” Herrlinger said. “We believe very strongly in the disability mantra of, nothing about us without us, and so it starts with first off employing members of these communities within our ranks. We never build for a community. We build with them.”
Herrlinger was joined on stage alongside retired Judge David S. Tatel, Mike Buckley, the Chair & CEO of Be My Eyes and Disability reporter for The Post Amanda Morris. When asked about the future of accessibility for those that are blind, Patel shared a touching sentiment many in the disability space resonate with.
“It’s anything that improves and enhances my independence, and enhances it seamlessly is with what I look for,” Tatel said. “That’s it. Independence, independence, independence.”
The post 6 takeaways from The Washington Post Futurist Tech Summit in D.C. appeared first on The Mozilla Blog.
CDT Joins Mozilla, Civil Society Orgs, and Leading Academics in Urging U.S. Secretary of Commerce to Protect AI ... - Center for Democracy and Technology
How AI is unfairly targeting and discriminating against Black people
The rise of Artificial Intelligence (AI) is here, and it’s bringing a new era of technology that is already creating and impacting the world. It was the story of 2023, and its emphasis isn’t going anywhere anytime soon.
While the creative growth of AI occurring so rapidly is a fascinating development for our society, it’s important to remember its harms that cannot be ignored, especially pertaining to racial bias and discrimination against African-Americans.
In recent years, there has been research revealing that AI technologies have struggled to identify images and speech patterns of nonwhite people. Black AI researchers at tech giants creating AI technology have raised concerns about its harms against the Black community.
The concerns surrounding AI’s racial biases and harms against Black people are serious and should be a big focus as 2024 gets underway. We invited University of Michigan professor, Harvard Faculty Associate and former Mozilla Foundation Senior Fellow in Trustworthy AI, Apryl Williams, to dive into this topic further. Williams studies experiences of gender and race at the intersection of digital spaces and algorithmic technocultures, and her most recent book, “Not My Type: Automating Sexual Racism in Online Dating,” exposes how race-based discrimination is a fundamental part of the most popular and influential dating algorithms.
To start, as a professor, I’m curious to know: How aware do you think students are of the dangers of the technology they’re using? Beyond the simple things like screen time notifications they might get, and more about AI problems, misinformation, etc.?
They don’t know. I show two key documentaries in my classes every semester. I teach a class called “Critical Perspectives on the Internet.” And then I have another class that’s called “Critical AI” and in both of those classes, the students are always shook. They always tell me, “You ruin everything for me, I can never look at the world the same,” which is great. That’s my goal. I hope that they don’t look at the world the same when they leave my classes, of course. But I show them “Coded Bias” by Shalini Kantayya and when they watched that just this past semester they were like, “I can’t believe this is legal, like, how are they using facial recognition everywhere? How are they able to do these things on our phones? How do they do this? How do they do that? I can’t believe this is legal. And why don’t people talk about it?” And I’m like, “Well, people do talk about it. You guys just aren’t necessarily keyed into the places where people are talking about.” And I think that’s one of the feelings of sort of like these movements that we’re trying to build is that we’re not necessarily tapped into the kinds of places young people go to get information.
We often assume that AI machines are neutral in terms of race, but research has shown that some of them are not and can have biases against Black people. When we think about where this problem stems from, is it fair to say it begins with the tech industry’s lack of representation of people who understand and can work to address the potential harms of these technologies?
I would say, yes, that is a huge part of it. But the actual starting point is the norms of the tech industry. So we know that the tech industry was created by and large by the military, industrial, complex — like the internet was a military device. And so because of that, a lot of the inequity or like inequality, social injustice of the time that the internet work was created were baked into the structure of the internet. And then, of course, industries that spring up from the internet, right? We know that the military was using the internet for surveillance. And look now, we have in 2024, widespread surveillance of Black communities, of marginalized communities, of undocumented communities, right? So really, it’s the infrastructure of the internet that was built to support white supremacy, I would say, is the starting point. And because the infrastructure of the internet and of the tech industry was born from white supremacy, then, yes, we have these hiring practices, and not just the hiring practices, but hiring practices where, largely, they are just hiring the same kinds of people — Cisgender, hetero white men. Increasingly white women, but still we’re not seeing the kinds of diversity that we should be seeing if we’re going to reach demographic parity. So we have the hiring. But then also, we have just the norms of the tech industry itself that are really built to service, I would say, the status quo, they’re not built to disrupt. They’re built to continue the norm. And if people don’t stop and think about that, then, yeah, we’re going to see the replication of all this bias because U.S. society was built on bias, right? Like it is a stratified society inherently. And because of that, we’re always going to see that stratification in the tech industry as well.
Issues of bias in AI tend to impact the people who are rarely in positions to develop the technology. How do you think we can enable AI communities to engage in the development and governance of AI to get it where it’s working toward creating systems that embrace the full spectrum of inclusion?
Yes, we should enable it. But also the tech industry, like people in these companies, need to sort of take the onus on themselves to reach out to communities in which they are going to deploy their technology, right? So if your target audience, let’s say on TikTok, is Black content creators, you need to be reaching out to Black content creators and Black communities before you launch an algorithm that targets those people. You should be having them at your headquarters. You should be doing listening sessions. You should be elevating Black voices. You should be listening to people, right? Listening to the concerns, having support teams in place, before you launch the technology, right? So instead of retroactively trying to Band-aid it when you have an oops or like a bad PR moment, you should be looking to marginalize communities as experts on what they need and how they see technology being implemented in their lives.
A lot of the issues with these technologies in relation to Black people is that they are not designed for Black people — and even the people they are designed for run into problems. It feels like this is a difficult spot for everyone involved?
Yeah, that’s an interesting question. I feel like it’s really hard for good people on the inside of tech companies to actually say, “Hey, this thing that we’re building might be generating money, but it’s not generating long-term longevity,” right? Or health for our users. And I get that — not every tech company is health oriented. They may act like they are, but they’re not, like to a lot of them, money is their bottom line. I really think it’s up to sort of like movement builders and tech industry shakers to say or to be able to create buy-in for programs, algorithms, ideas, that foster equity. But we have to be able to create buy-in for that. So that might look like, “Hey, maybe we might lose some users on this front end when we implement this new idea, but we’re going to gain a whole lot more users.” Folks of color, marginalized users, queer users, trans users, if they feel like they can trust us, and that’s worth the investment, right? So it’s really just valuing the whole person, rather than just sort of valuing the face value of the money only or what they think it is, but looking to see the potential of what would happen if people felt like their technology was actually trustworthy.
AI is rapidly growing. What are things we can add to it as it evolves, and what are things we should work to eliminate?
I would say we need to expand our definition of safety. I think that safety should fundamentally include your mental health and well-being, and if the company that you’re using it for to find intimacy or to connect with friends is not actually keeping you safe as a person of color, as a trans person, as a queer person, then you can’t really have like full mental wellness if you are constantly on high alert, you’re constantly in this anxious position, you’re having to worry that your technology is exploiting you, right? So, if we’re going to have all of this buzz that I’m seeing about trust and safety, that can’t just stop at the current discourse that we’re having on trust and safety. It can’t just be about protecting privacy, protecting data, protecting white people’s privacy. That has to include reporting mechanisms for users of color when they encounter abuse. Whether that is racism or homophobia, right? Like it needs to be more inclusive. I would say that the way that we think about trust and safety and automated or algorithmic systems needs to be more inclusive. We really need to widen the definition of safety. And probably the definition of trust also.
In terms of subtracting, they’re just a lot of things that we shouldn’t be doing, that we’re currently doing. Honestly, the thing that we need to subtract the most is this idea that we move fast and break things in tech culture. It’s sort of like, we are just moving for the sake of innovation. We might really need to dial back on this idea of moving for the sake of innovation, and actually think about moving towards a safer humanity for everybody, and designing with that goal in mind. We can innovate in a safe way. We might have to sacrifice speed, a nd I think we need to say, it’s okay to sacrifice speed in some cases.
When I started to think about the dangers of AI, I immediately remembered the situation with Robert Williams a few years ago, when he was wrongly accused by police that used AI facial recognition. There is more to it than just the strange memes and voice videos people create. What are the serious real world harms that you think of when it comes to Black people and AI that people are overlooking?
I don’t know that it’s overlooked, but I don’t think that Black people are aware of the amount of surveillance of everyday technologies. When you go to the airport, even if you’re not using Clear or other facial recognition technology at the airport for expedited security, they’re still using facial recognition technology. When you’re crossing borders, when you are even flying domestically, they’re still using that tech to look at your face. You look into the camera, they take your picture. They compare it to your ID. Like, that is facial recognition technology. I understand that that is for our national safety, but that also means that they’re collecting a lot of data on us. We don’t know what happens with that data. We don’t know if they keep it for 24 hours or if they keep it for 24 years. Are they keeping logs of what your face looks like every time you go? In 50 years, are we going to see a system that’s like “We’ve got these TSA files, and we’re able to track your aging from the time that you were 18 to the time that you’re 50, just based on your TSA data,” right? Like, we really don’t know what’s happening with the data. And that’s just one example.
We have constant surveillance, especially in our cars. The smarter our cars get, the more they’re surveilling us. We are seeing increasing use of those systems and cars being used, and police cases to see if you were paying attention. Were you talking on your phone? Were you texting and driving? Things like that. There is automation in cars that’s designed to identify people and to stop right to avoid hitting you. And as we know, a lot of the systems misidentify Black people as trash cans, and will instead hit them. There are so many instances where AI is part of our life, and I don’t think people realize the depth of which it really does drive our lives. And I think that’s the thing that scares me the most for people of color is that we don’t understand just how much AI is part of our everyday life. And I wish people would stop and sort of think about, yes, I get easy access to this thing, but what am I trading off to get that easy access? What does that mean for me? And what does that mean for my community? We have places like Project Blue light, Project Green Light, where those systems are heavily surveilled in order to “protect communities.” But are those created to protect white communities at the expense of Black and brown communities? Right? That’s what we have to think about when we say that these technologies, especially surveillance technologies, are being used to protect people, who are they protecting? And who are they protecting people from? And is that idea that they’re protecting people from a certain group of people realistic? Or is that grounded in some cultural bias that we have.
Looking bigger picture this year: It’s an election year and AI will certainly be a large talking point for candidates. Regardless of who wins this fall, in what ways do you think the administration can ensure that policies and enforcement are instilled to address AI to make sure that racial and other inequities don’t continue and evolve?
They need to enforce or encourage that tech companies have the onus of transparency on them. There needs to be some kind of legislative prompting, there has to be some kind of responsibility where tech companies actually suffer consequences, legal consequences, economic consequences, when they violate trust with the public, when they extract data without telling people. There also needs to be more two-way conversations. Often tech companies will just tell you, “These are the terms of service, you have to agree with them,” and if you don’t, you opt-out, that means you can’t use the tech. There needs to be some kind of system where tech companies can say, “Okay, we’re thinking about rolling this out or updating our terms of service in this way, how does the community feel about that?” And a way that really they can be accountable to their users. I think we really just need some legislation that makes tech companies sort of put their feet to the fire in terms of them actually having responsibility to their users.
When it comes to fighting against racial biases and struggles, sometimes the most important people that can help create change and bring awareness are those not directly impacted by what’s going on — for example, a white person being an ally and protesting for a Black person. What do you think most normal people can do to influence change and bring awareness to AI challenges for Black people?
I would say, for those people who are in the know about what tech companies are doing, talk about that with your kids, right? When you’re sitting down and your kids are telling you about something that their friend posted, that’s a perfect time to be like, “Let’s talk about that technology that your friend is using or that you’re using.” Did you know that on TikTok, this happens? Did you know that on TikTok, often Black creator voices are hidden, or Black content creators are shadow-banned? Did you know what happens on Instagram? These kinds of regular conversations, that way, these kinds of tech injustices are part of the everyday vernacular for kids as they’re coming up so that they can be more aware, and also so that they can advocate for themselves and for their communities.
The post How AI is unfairly targeting and discriminating against Black people appeared first on The Mozilla Blog.
Dr. J. Nathan Matias on leading technology research for better digital rights
At Mozilla, we know we can’t create a better future alone, that is why each year we will be highlighting the work of 25 digital leaders using technology to amplify voices, effect change, and build new technologies globally through our Rise 25 Awards. These storytellers, innovators, activists, advocates. builders and artists are helping make the internet more diverse, ethical, responsible and inclusive.
This week, we chatted with winner Dr. J. Nathan Matias, a professor at Cornell University leading technology research to create change and impact digital rights. He leads the school’s Citizen and Technology Lab (CAT) and is the co-founder of the Coalition for Independent Technology Research, a nonprofit defending the right to ethically study the impact of tech on society. We talk with Matias about his start in citizen science, his work advocating for researchers’ rights and more.
As a professor at Cornell, how would you gauge where students and Gen Z are at in terms of knowing the dangers of the internet?
As a researcher, I am very aware that my students are one narrow slice of Americans. I teach communication and technology. I teach this 500 student class and I think the students I teach hear about people’s concerns, about technology, through media, through what they see online. And they’re really curious about what if that is true and what we can do about it. That’s one of the great joys of being a professor, that I can introduce students to what we know, thanks to research and to all the advocacy and journalism, and also to what we don’t know and encourage students to help create the answers for themselves, their communities and future generations.
To kind of go a little bit even further, as a professor, what are the things that you try to instill with them, or what are core concepts that you think are really important for them to know and try to hammer down to them about the internet and the social impacts of all of these platforms?
If I’m known for one thing, it’s the idea that knowledge and power about digital technologies shouldn’t be constrained to just within the walls of the universities and tech companies. Throughout my classes and throughout my work, I actively collaborate with and engage with the general public to understand what people’s fears are to collect evidence and to inform accountability. And so, my students had the opportunity to see how that works and participate in it themselves. And I think that’s especially important, because yeah, people come to a university to learn and grow and learn from what scholars have said before, but also, if we come out of our degrees without an appreciation for the deeply held knowledge that people have outside of universities, I think that’s a missed opportunity.
Beyond the data you collect in your field, what other types of data collection out there creates change and inspires you to continue the work that you do?
I’m often inspired by people who do environmental citizen science because many of them live in context. We all live in contexts where our lives and our health and our futures are shaped by systems and infrastructures that are invisible, and that we might not appear to have much power over, right? It could be air or water, or any number of other environmental issues. And it’s similar for our digital environments. I’m often inspired by people who do work for data collection and advocacy and science on the environment when thinking about what we could do for our digital worlds. Last summer, I spent a week with a friend traveling throughout the California Central Valley, talking to educators, activists, organizers and farmworkers and communities working to understand and use data to improve their physical environment. We spent a day with Cesar Aguirre at the Central California Justice Network. You have neighborhoods in central California that are surrounded by oil wells and people are affected by the pollution that comes out of those wells — some of them have long been abandoned and are just leaking. And it’s hard to convince people sometimes that you’re experiencing a problem and to document the problem in a way that can get things to change. Cesar talked about ways that people used air sensors and told their stories and created media and worked in their local council and at a state level to document the health impacts of these oil wells and actually get laws changed at the state level to improve safety across the state. Whenever I encounter a story like that, whether it’s people in Central California or folks documenting oil spills in Louisiana or people just around the corner from Cornell — indigenous groups advocating for safe water and water rights in Onondaga Lake — I’m inspired by the work that people have to do and do to make their concerns and experiences legible to powerful institutions to create change. Sometimes it’s through the courts, sometimes it’s through basic science that finds new solutions. Sometimes it’s mutual aid, and often at the heart of these efforts, is some creative work to collect and share data that makes a difference.
 Dr.J Nathan Matias at Mozilla’s Rise25 award ceremony in October 2023.
Dr.J Nathan Matias at Mozilla’s Rise25 award ceremony in October 2023.
When it pertains to citizen science and the work that you do, what do you think is the biggest challenge you and other researchers face? And by that I mean, is it kind of the inaction of tech companies and a lot of these institutions? Or is it maybe just the very cold online climate of the world today?
It’s always hard to point to one. I think the largest one is just that we have a lot more work to do to help people realize that they can participate in documenting problems and imagining solutions. We’re so used to the idea that tech companies will take care of things for us, that when things go wrong, we might complain, but we don’t necessarily know how to organize or what to do next. And I think there’s a lot that we as people who are involved in these issues and more involved in them can do to make people aware and create pathways — and I know Mozilla has done a lot of work around awareness raising. Beyond that, we’ve kind of reached a point where I wish companies were indifferent, but the reality is that they’re actively working to hinder independent research and accountability. If you talk to anyone who’s behind the Coalition for Independent Tech Research, I think we would all say we kind of wish it we didn’t have to create it, because spending years building a network to support and defend researchers when they come under attack by governments or tech companies for accountability and transparency work for actually trying to solve problems, like, that’s not how you prefer to spend your time. But, I think that on the whole, the more people realize that we can do something, and that our perspective and experience matters, and that it can be part of the solution, the better off we are with our ability to document issues and imagine a better future. And as a result, when it involves organizing in the face of opposition, the more people we’ll have on that journey
Just looking at this year in general with so much going on, what do you think is the biggest challenge that we face this year and in the world? How do we combat it?
Here’s the one I’ve been thinking about. Wherever you live, we don’t live in a world where a person who has experienced a very real harm from a digital technology — whether it’s social media or some kind of AI system — can record that information and seek some kind of redress, or even know who to turn to, to address or fix the problem or harm. And we see this problem in so many levels, right? If someone’s worried about discrimination from an algorithm in hiring, who do you turn to? If you’re worried about the performance of your self-driving car, or you have a concern about mental health and social media this year? We haven’t had those cases in court yet. We’re seeing some efforts by governments to create standards and we’re seeing new laws proposed. But it’s still not possible, right? If you get a jar of food from the supermarket that has harmful bacteria, we kind of know what to do. There’s a way you can report it, and that problem can be solved for lots of people. But that doesn’t yet exist in these spaces. My hope for 2024 is that on whatever issue people are worried about or focused on, we’ll be able to make some progress towards knowing how to create those pathways. Whether it’s going to be work so that courts know how to make sense of evidence about digital technologies —and I think they’re going to be some big debates there — whether it’s going to involve these standards conversations that are happening in Europe and the U.S., around how to report AI incidents and how to determine whether an AI system is safe or not, or safe for certain purposes and any number of other issues. Will that happen and be solved this year? No, it’s a longer term effort. But how could we possibly say that we have a tech ecosystem that respects people’s rights and treats them well and is safe if we don’t even have basic ways for people to be heard when things go wrong, whether it’s by courts or companies, or elsewhere. And so I think that’s the big question that I’m thinking about both in our citizen science work and our broader policy work at Cat Lab.
There’s also a bigger problem that so many of these apps and platforms are very much dependent upon us having to doing something compared to them.
Absolutely. I think a lot of people have lost trust in companies to do things about those reports. Because companies have a history of ignoring them. In fact, my very first community participatory science project in this space, which started back in 2014, we pulled information from hundreds of women who faced online harassment. And we looked at the kinds of things they experienced. And then whether Twitter back then was responding to people’s reports. It revealed a bunch of systemic problems and how the company has handled it. I think we’ve reached the point where there’s some value in that reporting, and sometimes for good and sometimes those things are exploited for censorship purposes as well — people report things they disagree with to try to get it taken down. But even more deeply, those reports don’t get at the deeper systemic issues. They don’t address how to prevent problems in the first place, or how to create or how to change the underlying logics of those platforms, or how to incentivize companies differently, so that they don’t create the conditions for those problems in the first place. I think we’re all looking for what are the right entities? Some currently exist, some we’re going to have to create that will be able to take on what people experience and actually create change that matters.
We started Rise25 to celebrate Mozilla’s 25th anniversary, what do you hope people are celebrating in the next 25 years?
I love that question because my first true encounter with Mozilla would have been in 2012 at the Mozilla festival, and I was so inspired to be surrounded by a room of people who cared about making the Internet and our digital worlds better for people. And it was such a powerful statement that Mozilla convened people. Other tech institutions have these big events where the CEO stands on a stage and tells everyone why what they’re doing is revolutionary. And Mozilla did something radically different, which was to create a community and a space for people to envision the future together. I don’t know what the tech innovations or questions are going to be 25 years from now — there will probably be some enduring ones about access and equity and inclusion and safety for whatever the technologies are. My hope is that 25 years from now, Mozilla will continue to be an organization and a movement that listens and amplifies and supports a broad and diverse community to envision that together. It’s one of the things that makes Mozilla so special, and I think is one of the things that makes it so powerful.
What is one action you think that everybody can take to make the world and their lives online better?
I think the action to believe yourself when you notice something unusual, or have a question. And then to find other people who can corroborate and build a collective picture. Whether it’s by participating in the study at Cat Lab or something else. I have a respiratory disability, and it’s so easy to doubt your own experience and so hard to convince other people sometimes that what you’re experiencing is real. And so I think the biggest step we can do is to believe ourselves and to like, believe others when they talk about things they’ve experienced and are worried about but use that experience as the beginning of something larger, because it can be so powerful, and make such a huge difference when people believe in each other and take each other seriously.
What gives you hope about the future of our world?
So many things. I think every time I meet someone who is making things work under whatever circumstances they have — unsurprising as someone who does citizen and community science. I think about our conversations with Jasmine Walker, who is a community organizer who organizes these large spaces for Black communities online and has been doing it for ages and across many versions of technology and eras of time. And just to see the care and commitment that people have to their communities and families as it relates to technology — it could be our collaborators who are investigating hiring algorithms or communities we’ve talked to. We did a study that involved understanding the impact of smartphone design on people’s time use, and we met a bunch of people who are colorblind and advocates for accessibility. In each of those cases, there are people who care deeply about those around them and so much that they’re willing to do science to make a difference. I’m always inspired when we talk, and we find ways to support the work that they’re doing by creating evidence together that could make a difference. As scientists and researchers, we are sometimes along for the ride for just part of the journey. And so I’m always inspired when I see the commitment and dedication people have for a better world.
The post Dr. J. Nathan Matias on leading technology research for better digital rights appeared first on The Mozilla Blog.
Mozilla Firefox 124 Is Now Available for Download, Here’s What’s New - 9to5Linux
Mozilla trekt stekker uit privacyvriendelijke geolocatiedienst - Tablets en telefoons - Nieuws - Tweakers
Hacks.Mozilla.Org: Improving Performance in Firefox and Across the Web with Speedometer 3
In collaboration with the other major browser engine developers, Mozilla is thrilled to announce Speedometer 3 today. Like previous versions of Speedometer, this benchmark measures what we think matters most for performance online: responsiveness. But today’s release is more open and more challenging than before, and is the best tool for driving browser performance improvements that we’ve ever seen.
This fulfills the vision set out in December 2022 to bring experts across the industry together in order to rethink how we measure browser performance, guided by a shared goal to reflect the real-world Web as much as possible. This is the first time the Speedometer benchmark, or any major browser benchmark, has been developed through a cross-industry collaboration supported by each major browser engine: Blink, Gecko, and WebKit. Working together means we can build a shared understanding of what matters to optimize, and facilitates broad review of the benchmark itself: both of which make it a stronger lever for improving the Web as a whole.
And we’re seeing results: Firefox got faster for real users in 2023 as a direct result of optimizing for Speedometer 3. This took a coordinated effort from many teams: understanding real-world websites, building new tools to drive optimizations, and making a huge number of improvements inside Gecko to make web pages run more smoothly for Firefox users. In the process, we’ve shipped hundreds of bug fixes across JS, DOM, Layout, CSS, Graphics, frontend, memory allocation, profile-guided optimization, and more.
We’re happy to see core optimizations in all the major browser engines turning into improved responsiveness for real users, and are looking forward to continuing to work together to build performance tests that improve the Web.
The post Improving Performance in Firefox and Across the Web with Speedometer 3 appeared first on Mozilla Hacks - the Web developer blog.
Mozilla Thunderbird: Thunderbird for Android / K-9 Mail: February 2024 Progress Report

Welcome to a new report on the progress of transforming K-9 Mail into Thunderbird for Android. I hope you’ve enjoyed the extra day in February. We certainly did and used this opportunity to release a new stable version on February 29.
If you’re new to this series or the unusually long February made you forget what happened the previous month, you might want to check out January’s progress report.
New stable releaseWe spent most of our time in February getting ready for a new stable release – K-9 Mail 6.800. That mostly meant fixing bugs and usability issues reported by beta testers. Thanks to everyone who tested the app and reported bugs 
Read all about the new release in our blog post Towards Thunderbird for Android – K-9 Mail 6.800 Simplifies Adding Email Accounts.
What’s next?With the new account setup being mostly done, we’ll concentrate on the following two areas.
Material 3The question of whether to update the user interface to match the design used by the latest Android version seems to have always split the K-9 Mail user base. One group prefers that we work on adding new features instead. The other group wants their email app of choice to look similar to the apps that ship with Android.
Never updating the user interface to the latest design is not really an option. At some point all third-party libraries we’re using will only support the latest platform design. Not updating those libraries is also not an option because Android itself is constantly changing and requires app/library updates just to keep existing functionality working.
I think we found a good balance by not being the first ones to update to Material 3. By now a lot of other app developers have done so and countless bugs related to Material 3 have been found and fixed. So it’s a good time for us to start switching to Android’s latest design system now.
We’re currently still in a research phase to figure out what parts of the app need changing. Once that’s done, we’ll change the base theme and fix up the app screen by screen. You will be able to follow along by becoming a beta tester and installing K-9 Mail 6.9xx beta versions once those become available.
Android 14 compatibilityK-9 Mail is affected by a couple of changes that were introduced with Android 14. We’ve started to look into which parts of the app need to be updated to be able to target Android 14.
We’ve already identified these:
- Schedule exact alarms are denied by default – For some reason Google decided to also apply this change to apps targeting Android 13. We already mentioned this in our November/December 2023 progress report in the section “Push Not Working On Android 14”.
- Restrictions to implicit and pending intents – This affects the way we communicate with the crypto provider app (OpenKeychain) when using OpenPGP.
Our current plan is to include the necessary changes in updates to the K-9 Mail 6.8xx line.
Community Contributions- S Tanveer Hussain submitted a pull request to update the information about third-party libraries in K-9 Mail’s About screen (#7601)
- GitHub user LorenzHo provided a patch to not focus the recipient input field when the Compose screen was opened using a mailto: URI (#7623). Unfortunately, this change had to be backed out later because of unintended side effects. But we’re hopeful a modified version of this change will make it into the app soon.
Thank you for your contributions!
ReleasesIn February 2024 we published a new stable release:
- K-9 Mail v6.800 (2024-02-29)
… and the following beta versions:
- K-9 Mail v6.715 (beta) (2024-02-01)
- K-9 Mail v6.716 (beta) (2024-02-13)
- K-9 Mail v6.717 (beta) (2024-02-16)
The post Thunderbird for Android / K-9 Mail: February 2024 Progress Report appeared first on The Thunderbird Blog.
Adrian Gaudebert: Killing two birds with one deck in Dawnmaker
Let's face it: Dawnmaker still has some important flaws. We're aware of that, and we are working on those flaws. One of the biggest remaining problem with the game was that one of its core mechanics, the oppression of the Smog, was… well, not explained at all. If you didn't have a developer behind your back to tell you, there was almost no way you could understand it.
What's the oppression of the Smog, you ask? It is the fact that the Smog gets stronger the more the game progresses, and thus makes you consume luminoil faster. It's a simple formula that grows every time you shuffle your deck of cards: when that happens, your luminoil consumption increases by the level of your aerostation. We tried a few, small things to explain that mechanism: we added an animation to the Smog, making it grow darker and closer to your city, when the oppression increases. We also had a line in the luminoil tooltip showing how much luminoil is consumed by this oppression. But that was not nearly enough, and I started thinking about how to solve this with a complex UI inspired by Frostpunk. I am glad I did not go with that, as it would have been a nightmare to implement, and I now believe it would not have helped much.
 <figcaption>
<figcaption>
I sure am glad I did not try to implement this…
</figcaption>So, while I was busy not solving this problem, another one got to the front: the progression issue. You see, we have been struggling a lot with the meta progression we offer in Dawnmaker. We've made attempts at doing it Slay the Spire-like, with a map of limited paths and rewards after each stop. That doesn't work very well, the roguelike structure (the progression on the world map) around an already roguelike structure (a single region / city) was weird and sometimes frustrating. So we started thinking about doing it differently, more like Hades does it with its mirror. There would be a new resource that you'd gain after securing each region, and that resource could be spent in order to improve your starting party, making each new region a tad easier to secure.
We like this idea, but it causes another problem: if the game gets easier and easier, there will come a point when it will become boring, as the challenge will be lost. We thus need to have a progression in the difficulty just as we have one in the player's strength. Hades does that with the Heat system, where you can choose how you increase the challenge each time you play. We cannot easily do something similar, so I once again started thinking about a complex question: how can we increase the difficulty of the game? What levers to we have to do that in a way that is challenging and doesn't feel too artificial or frustrating? There's an easy answer to that: the length of the game and the number of lighthouses, which we use in the currently called "Discovery" game, where we increase both the level to reach and the number of lighthouses to repair in order to win a game as you progress on the map. But that is not enough for a long-term progression, as it would quickly feel completely artificial. Luckily, there was another feature we could use, and did not: the oppression of the Smog. That is were those two problems converged, and led me to a single solution solving both: turning the Smog's behavior into a deck of cards.

Using cards to represent the Smog's behavior increases the affordance of the game: Smog cards look like buildings cards, and they sort of work like them. It's a card that has an effect, that you can read at any time, and because it uses the same wording, abilities and display as the buildings, it's easy to interpret it. Changing the behavior simply means changing the card, and we can do a whole bunch of animations there to show that happening. We can also add tooltips around those elements to explain them further. That's a first big win! Now the second one is that we create and handle those decks in our content editor, and we can create as many cards and decks as we want. There we have it: near infinite difficulty progression, simply by making different Smog cards, and assembling them differently in various decks!
Note that we haven't done anything like that yet. So far we have only reproduced the previous system with cards. But the potential is here: when we start working on the meta progression, we can be confident that we'll have the tools to make the difficulty progress as well.
We definitely killed two nasty, vicious flying creatures with one deck. Neat!
This piece was initially sent out to the readers of our newsletter. Wanna join in on the fun? Head out to Dawnmaker's presentation page and fill the form. You'll receive regular stories about how we're making this game, the latest news of its development, as well as an exclusive access to Dawnmaker's alpha version!
The Rust Programming Language Blog: Announcing Rustup 1.27.0
The rustup team is happy to announce the release of rustup version 1.27.0. Rustup is the recommended tool to install Rust, a programming language that is empowering everyone to build reliable and efficient software.
If you have a previous version of rustup installed, getting rustup 1.27.0 is as easy as stopping any programs which may be using Rustup (e.g. closing your IDE) and running:
$ rustup self updateRustup will also automatically update itself at the end of a normal toolchain update:
$ rustup updateIf you don't have it already, you can get rustup from the appropriate page on our website.
What's new in rustup 1.27.0This long-awaited Rustup release has gathered all the new features and fixes since April 2023. These changes include improvements in Rustup's maintainability, user experience, compatibility and documentation quality.
Also, it's worth mentioning that Dirkjan Ochtman (djc) and rami3l (rami3l) have joined the team and are coordinating this new release.
At the same time, we have granted Daniel Silverstone (kinnison) and 二手掉包工程师 (hi-rustin) their well-deserved alumni status in this release cycle. Kudos for your contributions over the years and your continuous guidance on maintaining the project!
The headlines for this release are:
-
Basic support for the fish shell has been added. If you're using fish, PATH configs for your Rustup installation will be added automatically from now on.
Please note that this will only take effect on installation, so if you have already installed Rustup on your machine, you will need to reinstall it. For example, if you have installed Rustup via rustup.rs, simply follow rustup.rs's instructions again; if you have installed Rustup using some other method, you might want to reinstall it using that same method.
-
Rustup support for loongarch64-unknown-linux-gnu as a host platform has been added. This means you should be able to install Rustup via rustup.rs and no longer have to rely on loongnix.cn or self-compiled installations.
Please note that as of March 2024, loongarch64-unknown-linux-gnu is a "tier 2 platform with host tools", so Rustup is guaranteed to build for this platform. According to Rust's target tier policy, this does not imply that these builds are also guaranteed to work, but they often work to quite a good degree and patches are always welcome!
Full details are available in the changelog!
Rustup's documentation is also available in the rustup book.
ThanksThanks again to all the contributors who made rustup 1.27.0 possible!
- Anthony Perkins (acperkins)
- Tianqi (airstone42)
- Alex Gaynor (alex)
- Alex Hudspith (alexhudspith)
- Alan Somers (asomers)
- Brett (brettearle)
- Burak Emir (burakemir)
- Chris Denton (ChrisDenton)
- cui fliter (cuishuang)
- Dirkjan Ochtman (djc)
- Dezhi Wu (dzvon)
- Eric Swanson (ericswanson-dfinity)
- Prikshit Gautam (gautamprikshit1)
- hev (heiher)
- 二手掉包工程师 (hi-rustin)
- Kamila Borowska (KamilaBorowska)
- klensy (klensy)
- Jakub Beránek (Kobzol)
- Kornel (kornelski)
- Matt Harding (majaha)
- Mathias Brossard (mbrossard)
- Christian Thackston (nan60)
- Ruohui Wang (noirgif)
- Olivier Lemasle (olivierlemasle)
- Chih Wang (ongchi)
- Pavel Roskin (proski)
- rami3l (rami3l)
- Robert Collins (rbtcollins)
- Sandesh Pyakurel (Sandesh-Pyakurel)
- Waffle Maybe (WaffleLapkin)
- Jubilee (workingjubilee)
- WÁNG Xuěruì (xen0n)
- Yerkebulan Tulibergenov (yerke)
- Renovate Bot (renovate)
The Rust Programming Language Blog: crates.io: Download changes
Like the rest of the Rust community, crates.io has been growing rapidly, with download and package counts increasing 2-3x year-on-year. This growth doesn't come without problems, and we have made some changes to download handling on crates.io to ensure we can keep providing crates for a long time to come.
The ProblemThis growth has brought with it some challenges. The most significant of these is that all download requests currently go through the crates.io API, occasionally causing scaling issues. If the API is down or slow, it affects all download requests too. In fact, the number one cause of waking up our crates.io on-call team is "slow downloads" due to the API having performance issues.
Additionally, this setup is also problematic for users outside of North America, where download requests are slow due to the distance to the crates.io API servers.
The SolutionTo address these issues, over the last year we have decided to make some changes:
Starting from 2024-03-12, cargo will begin to download crates directly from our static.crates.io CDN servers.
This change will be facilitated by modifying the config.json file on the package index. In other words: no changes to cargo or your own system are needed for the changes to take effect. The config.json file is used by cargo to determine the download URLs for crates, and we will update it to point directly to the CDN servers, instead of the crates.io API.
Over the past few months, we have made several changes to the crates.io backend to enable this:
-
We announced the deprecation of "non-canonical" downloads, which would be harder to support when downloading directly from the CDN.
-
We changed how downloads are counted. Previously, downloads were counted directly on the crates.io API servers. Now, we analyze the log files from the CDN servers to count the download requests.
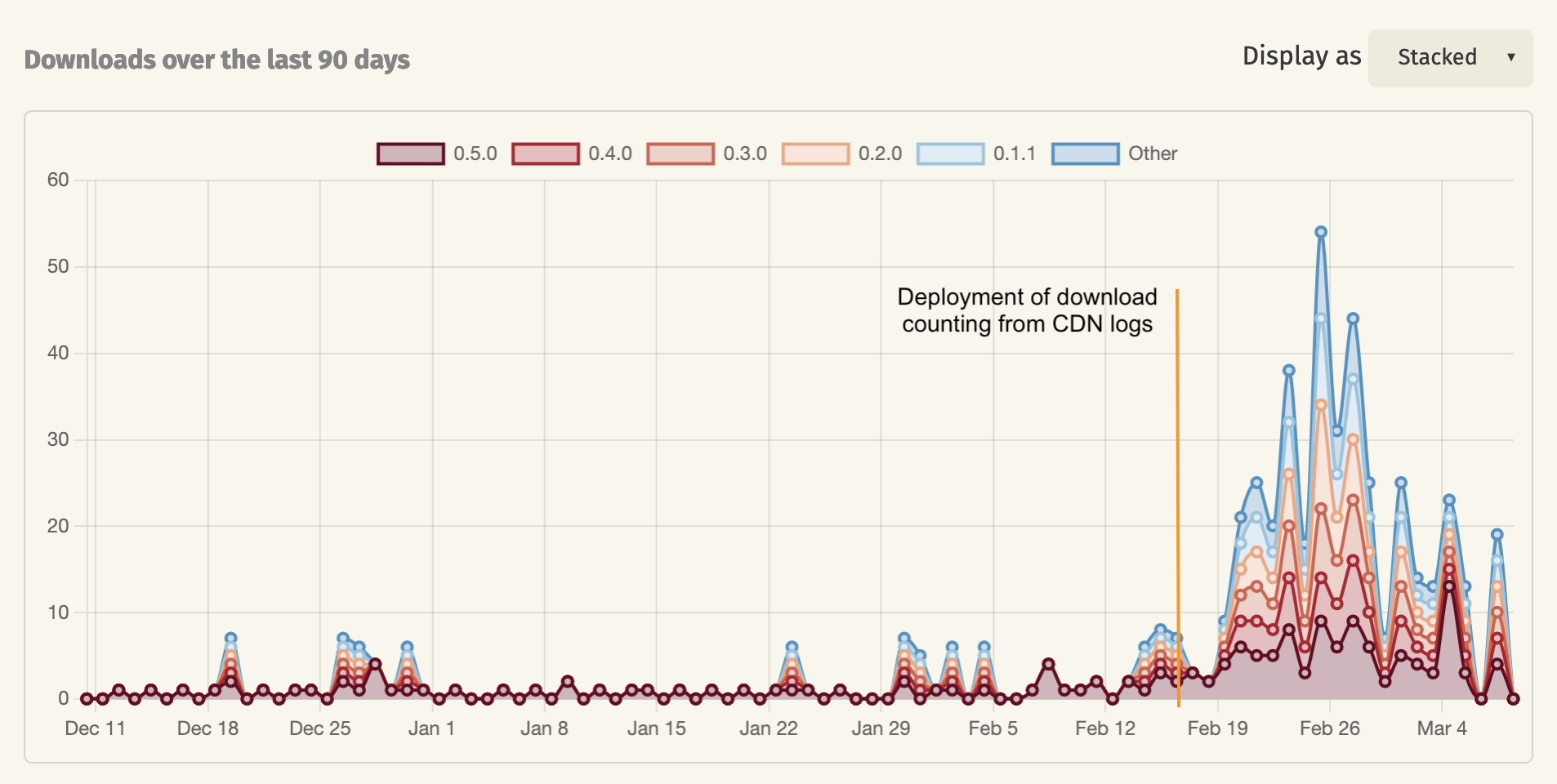
The latter change has caused the download numbers of most crates to increase, as some download requests were not counted before. Specifically, crates.io mirrors were often downloading directly from the CDN servers already, and those downloads had previously not been counted. For crates with a lot of downloads these changes will be barely noticeable, but for smaller crates, the download numbers have increased quite a bit over the past few weeks since we enabled this change.
Expected OutcomesWe expect these changes to significantly improve the reliability and speed of downloads, as the performance of the crates.io API servers will no longer affect the download requests. Over the next few weeks, we will monitor the performance of the system to ensure that the changes have the expected effects.
We have noticed that some non-cargo build systems are not using the config.json file of the index to build the download URLs. We will reach out to the maintainers of those build systems to ensure that they are aware of the change and to help them update their systems to use the new download URLs. The old download URLs will continue to work, but these systems will be missing out on the potential performance improvement.
We are excited about these changes and believe they will greatly improve the reliability of crates.io. We look forward to hearing your feedback!
Don Marti: privacy: I’d buy that for $20!
How much extra should you pay, or would you end up having to pay, to get privacy from surveillance ads? This is my attempt to come up with a high number for surveillance advertising’s impact on the content economy—the actual ad-supported information, entertainment, or other resource that that advertising is paying for. For now I’m going to make the most pro-surveillance assumptions, to try to come up with a high bound for the price of privacy.
To start with, total advertising, in all media, in the USA is about $960 per person which works out to a convenient $80 per month being spent on ads intended to reach you. So let’s start with the $80 and assume (to be as friendly as possible to the surveillance side…)
All advertisers prefer maximum surveillance
All ads are surveillance ads unless interfered with by privacy tools
Surveillance ads are 2x as valuable as non-surveillance ads
People who make content (writers, photographers, artists, musicians, editors…) get a similar large share of revenue from advertising spending as from other ways of supporting their work.
So, if you can somehow get total privacy protection, ads that reach you are worth only $40 per month total, instead of $80. Or, more realistically, if you can get halfway protected, your privacy is costing the content creators of the world $20 per month minus whatever goes to the intermediaries. That’s real money, but it’s on the scale of a few subscriptions or a fraction of an ISP bill, not privacy breaks the Internet economy as we know it money. According to one survey, the average US household spends $61/month on streaming video services. That’s per household, not per person, so at an average household size of 2.5, streaming alone is about $24 a person. could use some numbers for music, news and other services here too.
You might not want to agree with those three assumptions. Some ad money still gets spent on non-surveillance advertising, and surveillance advertising might not be twice as valuable as surveillance advertising in every medium. And different ways of supporting content have different transaction costs. If I install privacy tools that cost the surveillance business $100 in ad revenue per year, and at the same time I buy a subscription to 404 Media for $100 per year, I’m pretty sure I’m paying for a lot more content than the ads would have. The stack of service providers needed to run a subscription service takes a smaller bite of the subscription money than the ad agency/adtech stack takes of the ad money. And the publisher/intermediary split is always worse than it looks. Many of the publishers that show up in adtech’s reckoning of its impact are so-called made for advertising (MFA) sites, or sites that just run copyright-infringing or AI generated content. When a surveillance firm makes claims about ads supporting content, a lot of the ad money they count as the publisher’s share is not funding any new material at all.
Thomas Baekdal wrote, for every one person you could convince to subscribe, donate, become a member, or support you on Patreon…you would need 10,000 visitors to make the same amount from advertising. Or to put that into perspective, with only 100 subscribers, I could make the same amount of money as I used to earn from having one million visitors. It doesn’t look like you need to add $4 to your monthly subscription budget, to balance things out, every time you improve your privacy protection by 10%—that’s more of an unrealistically high estimate if you want to be on the safe side. A more realistic view on the impact of privacy tech is in Targeted advertising, platform competition and privacy. Making both personalized and non-personalized options available will make more money for the publishers, so publishers are better off letting the privacy people have privacy as a fair choice—so the privacy fraction of the audience is protected from being followed elsewhere in a way that drives down ad rates—while the personalized ads option remains available for those who want it.
The bigger problem is that platform companies that sit between advertiser and publisher are steadily chickenizing the companies on both sides of the ad market. Jakob Nielsen pointed out the problem for search engines back in 2006:
In the long run, every time companies increase the value of their online businesses, they end up handing over all that added value to the search engines. Any gain is temporary; once competing sites improve their profit-per-visitor enough to increase their search bids, they’ll drive up everybody’s cost of traffic.
Today, the problem continues in search, but also applies to big retail and social platforms. Direct to consumer brands must pay rent to platforms, and both brands and publishers are indirectly micromanaged by and for large platform companies, like drivers for Uber or Amazon. So it seems like there’s a big win available from antitrust cases. Putting a price on privacy is probably backwards. It would make more sense for legit sellers to promote and even pay for privacy tools among good customers, just for the fraud protection benefits. Money that a customer spends taking their kids to a bogus event advertised on social media can’t be spent on legit products or services. Brands that need to reach a high-privacy early adopter group are going to have some interesting post-surveillance options.
Something that’s harder to measure is that companies may be over-advertising to the point of inefficiency because advertising is (with extra, unwanted, surveillance in place) more measurable than other ways to spend company money. The direct mail saying is list, offer, package—you can get the highest returns by targeting the best-performing list of people, then by making a better product and/or a better price, and finally by improving the actual mail piece. If privacy goes up to the point where optimizing the list is harder to do, then the company has more incentive to invest in “offer” (product features, quality, service, price) and “package” (content marketing and ad creative).
One of the unconventional aspects of the open source trend of the 1990s/early 2000s was that open source companies like Red Hat were willing to say that they wanted the software market to be smaller in total. Most investors don’t like to hear that especially for an established industry. But a smaller, more restricted advertising industry in total might be more valuable to advertisers and consumers, by driving some investment into product improvements that are higher in value than, but less measurable than, advertising.
Bonus linksHow Google Blew Up Its Open Culture and Compromised Its Product
The Tech Industry Doesn’t Understand Consent
We’re not Meta support: State AGs tell Zuck to fix rampant account takeover problem
Tracking ads industry faces another body blow in the EU
Now the EU is asking questions about Meta’s ‘pay or be tracked’ consent model
Meta’s pay-or-consent model hides ‘massive illegal data processing ops’: lawsuit
Platforms are selling your work to AI vendors with impunity. They need to stop.
Wendy’s says ‘dynamic’ pricing won’t tack surge pricing onto your nuggets
Don’t let Reddit monetize your knowledge just so Google can train its AI
The Rentier Economy, Vulture Capital, and Enshittification
Google Reportedly Paying News Outlets to Unleash an Avalanche of AI Slop
If Online Ads Feel More Annoying, It’s Because They Are
It’s MFA Freedom Day! Celebrate By Fixing Your Supply Chain
Avast fined $16.5 million for ‘privacy’ software that actually sold users’ browsing data
Fake Funeral Live Stream Scams Are All Over Facebook
DTC Brands Are Trying Email, Since Social Alone Won’t Cut It
Wladimir Palant: Numerous vulnerabilities in Xunlei Accelerator application
Xunlei Accelerator (迅雷客户端) a.k.a. Xunlei Thunder by the China-based Xunlei Ltd. is a wildly popular application. According to the company’s annual report 51.1 million active users were counted in December 2022. The company’s Google Chrome extension 迅雷下载支持, while not mandatory for using the application, had 28 million users at the time of writing.
I’ve found this application to expose a massive attack surface. This attack surface is largely accessible to arbitrary websites that an application user happens to be visiting. Some of it can also be accessed from other computers in the same network or by attackers with the ability to intercept user’s network connections (Man-in-the-Middle attack).
It does not appear like security concerns were considered in the design of this application. Extensive internal interfaces were exposed without adequate protection. Some existing security mechanisms were disabled. The application also contains large amounts of third-party code which didn’t appear to receive any security updates whatsoever.
I’ve reported a number of vulnerabilities to Xunlei, most of which allowed remote code execution. Still, given the size of the attack surface it felt like I barely scratched the surface.
Last time Xunlei made security news, it was due to distributing a malicious software component. Back then it was an inside job, some employees turned rouge. However, the application’s flaws allowed the same effect to be easily achieved from any website a user of the application happened to be visiting.
Contents- What is Xunlei Accelerator?
- The built-in web browser
- The main application
- The XLLite application
- Plugin management
- Outdated components
- Reporting the issues
Wikipedia lists Xunlei Limited’s main product as a Bittorrent client, and maybe a decade ago it really was. Today however it’s rather difficult to describe what this application does. Is it a download manager? A web browser? A cloud storage service? A multimedia client? A gaming platform? It appears to be all of these things and more.
It’s probably easier to think of Xunlei as an advertising platform. It’s an application with the goal of maximizing profits through displaying advertising and selling subscriptions. As such, it needs to keep the users on the platform for as long as possible. That’s why it tries to implement every piece of functionality the user might need, while not being particularly good at any of it of course.
So there is a classic download manager that will hijack downloads initiated in the browser, with the promise of speeding them up. There is also a rudimentary web browser (two distinctly different web browsers in fact) so that you don’t need to go back to your regular web browser. You can play whatever you are downloading in the built-in media player, and you can upload it to the built-in storage. And did I mention games? Yes, there are games as well, just to keep you occupied.
Altogether this is a collection of numerous applications, built with a wide variety of different technologies, often implementing competing mechanisms for the same goal, yet trying hard to keep the outward appearance of a single application.
The built-in web browser The trouble with custom Chromium-based browsersCompanies love bringing out their own web browsers. The reason is not that their browser is any better than the other 812 browsers already on the market. It’s rather that web browsers can monetize your searches (and, if you are less lucky, also your browsing history) which is a very profitable business.
Obviously, profits from that custom-made browser are higher if the company puts as little effort into maintenance as possible. So they take the open source Chromium, slap their branding on it, maybe also a few half-hearted features, and they call it a day.
Trouble is: a browser has a massive attack surface which is exposed to arbitrary web pages (and ad networks) by definition. Companies like Mozilla or Google invest enormous resources into quickly plugging vulnerabilities and bringing out updates every six weeks. And that custom Chromium-based browser also needs updates every six weeks, or it will expose users to known (and often widely exploited) vulnerabilities.
Even merely keeping up with Chromium development is tough, which is why it almost never happens. In fact, when I looked at the unnamed web browser built into the Xunlei application (internal name: TBC), it was based on Chromium 83.0.4103.106. Being released in May 2020, this particular browser version was already three and a half years old at that point. For reference: Google fixed eight actively exploited zero-day vulnerabilities in Chromium in the year 2023 alone.
Among others, the browser turned out to be vulnerable to CVE-2021-38003. There is this article which explains how this vulnerability allows JavaScript code on any website to gain read/write access to raw memory. I could reproduce this issue in the Xunlei browser.
Protections disabledIt is hard to tell whether not having a pop-up blocker in this browser was a deliberate choice or merely a consequence of the browser being so basic. Either way, websites are free to open as many tabs as they like. Adding --autoplay-policy=no-user-gesture-required command line flag definitely happened intentionally however, turning off video autoplay protections.
It’s also notable that Xunlei revives Flash Player in their browser. Flash Player support has been disabled in all browsers in December 2020, for various reasons including security. Xunlei didn’t merely decide to ignore this reasoning, they shipped Flash Player 29.0.0.140 (released in April 2018) with their browser. Adobe support website lists numerous Flash Player security fixes published after April 2018 and before end of support.
Censorship includedInterestingly, Xunlei browser won’t let users visit the example.com website (as opposed to example.net). When you try, the browser redirects you to a page on static.xbase.cloud. This is an asynchronous process, so chances are good that you will catch a glimpse of the original page first.

Automated translation of the text: “This webpage contains illegal or illegal content and access has been stopped.”
As it turns out, the application will send every website you visit to an endpoint on api-shoulei-ssl.xunlei.com. That endpoint will either accept your choice of navigation target or instruct to redirect you to a different address. So when to navigate to example.com the following request will be sent:
POST /xlppc.blacklist.api/v1/check HTTP/1.1 Content-Length: 29 Content-Type: application/json Host: api-shoulei-ssl.xunlei.com {"url":"http://example.com/"}And the server responds with:
{ "code": 200, "msg": "ok", "data": { "host": "example.com", "redirect": "https://static.xbase.cloud/file/2rvk4e3gkdnl7u1kl0k/xappnotfound/#/unreach", "result": "reject" } }Interestingly, giving it the address http://example.com./ (note the trailing dot) will result in the response {"code":403,"msg":"params error","data":null}. With the endpoint being unable to handle this address, the browser will allow you to visit it.
Native APIIn an interesting twist, the Xunlei browser exposed window.native.CallNativeFunction() method to all web pages. Calls would be forwarded to the main application where any plugin could register its native function handlers. When I checked, there were 179 such handlers registered, though that number might vary depending on the active plugins.
Among the functions exposed were ShellOpen (used Windows shell APIs to open a file), QuerySqlite (query database containing download tasks), SetProxy (configure a proxy server to be used for all downloads) or GetRecentHistorys (retrieve browsing history for the Xunlei browser).
My proof-of-concept exploit would run the following code:
native.CallNativeFunction("ShellOpen", "c:\\windows\\system32\\calc.exe");This would open the Windows Calculator, just as you’d expect.
Now this API was never meant to be exposed to all websites but only to a selected few very “trusted” ones. The allowlist here is:
[ ".xunlei.com", "h5-pccloud.onethingpcs.com", "h5-pccloud.test.onethingpcs.com", "h5-pciaas.onethingpcs.com", "h5-pccloud.onethingcloud.com", "h5-pccloud-test.onethingcloud.com", "h5-pcxl.hiveshared.com" ]And here is how access was being validated:
function isUrlInDomains(url, allowlist, frameUrl) { let result = false; for (let index = 0; index < allowlist.length; ++index) { if (url.includes(allowlist[index]) || frameUrl && frameUrl.includes(allowlist[index])) { result = true; break; } } return result; }As you might have noticed, this doesn’t actually validate the host name against the list but looks for substring matches in the entire address. So https://malicious.com/?www.xunlei.com is also considered a trusted address, allowing for a trivial circumvention of this “protection.”
Getting into the Xunlei browserNow most users hopefully won’t use Xunlei for their regular browsing. These should be safe, right?
Unfortunately not, as there is a number of ways for webpages to open the Xunlei browser. The simplest way is using a special thunderx:// address. For example, thunderx://eyJvcHQiOiJ3ZWI6b3BlbiIsInBhcmFtcyI6eyJ1cmwiOiJodHRwczovL2V4YW1wbGUuY29tLyJ9fQ== will open the Xunlei browser and load https://example.com/ into it. From the attacker’s point of view, this approach has a downside however: modern browsers ask the user for confirmation before letting external applications handle addresses.
There are alternatives however. For example, the Xunlei browser extension (28 million users according to Chrome Web Store) is meant to pass on downloads to the Xunlei application. It could be instrumented into passing on thunderx:// links without any user interaction however, and these would immediately open arbitrary web pages in the Xunlei browser.
More ways to achieve this are exposed by the XLLite application’s API which is introduced later. And that’s likely not even the end of it.
The fixesWhile Xunlei never communicated any resolution of these issues to me, as of Xunlei Accelerator 12.0.8.2392 (built on February 2, 2024 judging by executable signatures) several changes have been implemented. First of all, the application no longer packages Flash Player. It still activates Flash Player if it is installed on the user’s system, so some users will still be exposed. But chances are good that this Flash Player installation will at least be current (as much as software can be “current” three years after being discontinued).
The isUrlInDomains() function has been rewritten, and the current logic appears reasonable. It will now only check the allowlist against the end of the hostname, matches elsewhere in the address won’t be accepted. So this now leaves “only” all of the xunlei.com domain with access to the application’s internal APIs. Any cross-site scripting vulnerability anywhere on this domain will again put users at risk.
The outdated Chromium base appears to remain unchanged. It still reports as Chromium 83.0.4103.106, and the exploit for CVE-2021-38003 still succeeds.
The browser extension 迅雷下载支持 also received an update, version 3.48 on January 3, 2024. According to automated translation, the changelog entry for this version reads: “Fixed some known issues.” The fix appears to be adding a bunch of checks for the event.isTrusted property, making sure that the extension can no longer be instrumented quite as easily. Given these restrictions, just opening the thunderx:// address directly likely has higher chances of success now, especially when combined with social engineering.
The main application Outdated Electron frameworkThe main Xunlei application is based on the Electron framework. This means that its user interface is written in HTML and displayed via the Chromium web browser (renderer process). And here again it’s somewhat of a concern that the Electron version used is 83.0.4103.122 (released in June 2020). It can be expected to share most of the security vulnerabilities with a similarly old Chromium browser.
Granted, an application like that should be less exposed than a web browser as it won’t just load any website. But it does work with remote websites, so vulnerabilities in the way it handles web content are an issue.
Cross-site scripting vulnerabilitiesBeing HTML-based, the Xunlei application is potentially vulnerable to cross-site scripting vulnerabilities. For most part, this is mitigrated by using the React framework. React doesn’t normally work with raw HTML code, so there is no potential for vulnerabilities here.
Well, normally. Unless dangerouslySetInnerHTML property is being used, which you should normally avoid. But it appears that Xunlei developers used this property in a few places, and now they have code displaying messages like this:
$createElement("div", { staticClass: "xly-dialog-prompt__text", domProps: { innerHTML: this._s(this.options.content) } })If message content ever happens to be some malicious data, it could create HTML elements that will result in execution of arbitrary JavaScript code.
How would malicious data end up here? Easiest way would be via the browser. There is for example the MessageBoxConfirm native function that could be called like this:
native.CallNativeFunction("MessageBoxConfirm", JSON.stringify({ title: "Hi", content: `<img src="x" onerror="alert(location.href)">`, type: "info", okText: "Ok", cancelVisible: false }));When executed on a “trusted” website in the Xunlei browser, this would make the main application display a message and, as a side-effect, run the JavaScript code alert(location.href).
Impact of executing arbitrary code in the renderer processElectron normally sandboxes renderer processes, making certain that these have only limited privileges and vulnerabilities are harder to exploit. This security mechanism is active in the Xunlei application.
However, Xunlei developers at some point must have considered it rather limiting. After all, their user interface needed to perform lots of operations. And providing a restricted interface for each such operation was too much effort.
So they built a generic interface into the application. By means of messages like AR_BROWSER_REQUIRE or AR_BROWSER_MEMBER_GET, the renderer process can instruct the main (privileged) process of the application to do just about anything.
My proof-of-concept exploit successfully abused this interface by loading Electron’s shell module (not accessible to sandboxed renderers by regular means) and calling one of its methods. In other words, the Xunlei application managed to render this security boundary completely useless.
The (lack of) fixesLooking at Xunlei Accelerator 12.0.8.2392, I could not recognize any improvements in this area. The application is still based on Electron 83.0.4103.122. The number of potential XSS vulnerabilities in the message rendering code didn’t change either.
It appears that Xunlei called it a day after making certain that triggering messages with arbitrary content became more difficult. I doubt that it is impossible however.
The XLLite application Overview of the applicationThe XLLite application is one of the plugins running within the Xunlei framework. Given that I never created a Xunlei account to see this application in action, my understanding of its intended functionality is limited. Its purpose however appears to be integrating the Xunlei cloud storage into the main application.
As it cannot modify the main application’s user interface directly, it exposes its own user interface as a local web server, on a randomly chosen port between 10500 and 10599. That server essentially provides static files embedded in the application, all functionality is implemented in client-side JavaScript.
Privileged operations are provided by a separate local server running on port 21603. Some of the API calls exposed here are handled by the application directly, others are forwarded to the main application via yet another local server.
I originally got confused about how the web interface accesses the API server, with the latter failing to implement CORS correctly – OPTION requests don’t get a correct response, so that only basic requests succeed. It appears that Xunlei developers didn’t manage to resolve this issue and instead resorted to proxying the API server on the user interface server. So any endpoints available on the API server are exposed by the user interface server as well, here correctly (but seemingly unnecessarily) using CORS to allow access from everywhere.
So the communication works like this: the Xunlei application loads http://127.0.0.1:105xx/ in a frame. The page then requests some API on its own port, e.g. http://127.0.0.1:105xx/device/now. When handling the request, the XLLite application requests http://127.0.0.1:21603/device/now internally. And the API server handler within the same process responds with the current timestamp.
This approach appears to make little sense. However, it’s my understanding that Xunlei also produces storage appliances which can be installed on the local network. Presumably, these appliances run identical code to expose an API server. This would also explain why the API server is exposed to the network rather than being a localhost-only server.
The “pan authentication”With quite a few API calls having the potential to do serious damage or at the very least expose private information, these need to be protected somehow. As mentioned above, Xunlei developers chose not to use CORS to restrict access but rather decided to expose the API to all websites. Instead, they implemented their own “pan authentication” mechanism.
Their approach of generating authentication tokens was taking the current timestamp, concatenating it with a long static string (hardcoded in the application) and hashing the result with MD5. Such tokens would expire after 5 minutes, apparently an attempt to thwart replay attacks.
They even went as far as to perform time synchronization, making sure to correct for deviation between the current time as perceived by the web page (running on the user’s computer) and by the API server (running on the user’s computer). Again, this is something that probably makes sense if the API server can under some circumstances be running elsewhere on the network.
Needless to say that this “authentication” mechanism doesn’t provide any value beyond very basic obfuscation.
Achieving code execution via plugin installationThere are quite a few interesting API calls exposed here. For example, the device/v1/xllite/sign endpoint would sign data with one out of three private RSA keys hardcoded in the application. I don’t know what this functionality is used for, but I sincerely hope that it’s as far away from security and privacy topics as somehow possible.
There is also the device/v1/call endpoint which is yet another way to open a page in the Xunlei browser. Both OnThunderxOpt and OpenNewTab calls allow that, the former taking a thunderx:// address to be processed and the latter a raw page address to be opened in the browser.
It’s fairly obvious that the API exposes full access to the user’s cloud storage. I chose to focus my attention on the drive/v1/app/install endpoint however, which looked like it could do even more damage. This endpoint in fact turned out to be a way to install binary plugins.
I couldn’t find any security mechanisms preventing malicious software to be installed this way, apart from the already mentioned useless “pan authentication.” However, I couldn’t find any actual plugins to use as an example. In the end I figured out that a plugin had to be packaged in an archive containing a manifest.yaml file like the following:
ID: Exploit Title: My exploit Description: This is an exploit Version: 1.0.0 System: - OS: windows ARCH: 386 Service: ExecStart: Exploit.exe ExecStop: Exploit.exeThe plugin would install successfully under Thunder\Profiles\XLLite\plugin\Exploit\1.0.1\Exploit but the binary wouldn’t execute for some reason. Maybe there is a security mechanism that I missed, or maybe the plugin interface simply isn’t working yet.
Either way, I started thinking: what if instead of making XLLite run my “plugin” I would replace an existing binary? It’s easy enough to produce an archive with file paths like ..\..\..\oops.exe. However, the Go package archiver used here has protection against such path traversal attacks.
The XLLite code deciding which folder to put the plugin into didn’t have any such protections on the other hand. The folder is determined by the ID and Version values of the plugin’s manifest. Messing with the former is inconvenient, it being present twice in the path. But setting the “version” to something like ..\..\.. achieved the desired results.
Two complications:
- The application to be replaced cannot be running or the Windows file locking mechanism will prevent it from being replaced.
- The plugin installation will only replace entire folders.
In the end, I chose to replace Xunlei’s media player for my proof of concept. This one usually won’t be running and it’s contained in a folder of its own. It’s also fairly easy to make Xunlei run the media player by using a thunderx:// link. Behold, installation and execution of a malicious application without any user interaction.
Remember that the API server is exposed to the local network, meaning that any devices on the network can also perform API calls. So this attack could not merely be executed from any website the user happened to be visiting, it could also be launched by someone on the same network, e.g. when the user is connected to a public WiFi.
The fixesAs of version 3.19.4 of the XLLite plugin (built January 25, 2024 according to its digital signature), the “pan authentication” method changed to use JSON Web Tokens. The authentication token is embedded within the main page of the user interface server. Without any CORS headers being produced for this page, the token cannot be extracted by other web pages.
It wasn’t immediately obvious what secret is being used to generate the token. However, authentication tokens aren’t invalidated if the Xunlei application is restarted. This indicates that the secret isn’t being randomly generated on application startup. The remaining possibilities are: a randomly generated secret stored somewhere on the system (okay) or an obfuscated hardcoded secret in the application (very bad).
While calls to other endpoints succeed after adjusting authentication, calls to the drive/v1/app/install endpoint result in a “permission denied” response now. I did not investigate whether the endpoint has been disabled or some additional security mechanism has been added.
Plugin management The odditiesXLLite’s plugin system is actually only one out of at least five completely different plugin management systems in the Xunlei application. One other is the main application’s plugin system, the XLLite application is installed as one such plugin. There are more, and XLLiveUpdateAgent.dll is tasked with keeping them updated. It will download the list of plugins from an address like http://upgrade.xl9.xunlei.com/plugin?os=10.0.22000&pid=21&v=12.0.3.2240&lng=0804 and make sure that the appropriate plugins are installed.
Note the lack of TLS encryption here which is quite typical. Part of the issue appears to be that Xunlei decided to implement their own HTTP client for their downloads. In fact, they’ve implemented a number of different HTTP clients instead of using any of the options available via the Windows API for example. Some of these HTTP clients are so limited that they cannot even parse uncommon server responses, much less support TLS. Others support TLS but use their own list of CA certificates which happens to be Mozilla’s list from 2016 (yes, that’s almost eight years old).
Another common issue is that almost all these various update mechanisms run as part of the regular application process, meaning that they only have user’s privileges. How do they manage to write to the application directory then? Well, Xunlei solved this issue: they made the application directory writable with user’s privileges! Another security mechanism successfully dismantled. And there is a bonus: they can store application data in the same directory rather than resorting to per-user nonsense like AppData.
Altogether, you better don’t run Xunlei Accelerator on untrusted networks (meaning: any of them?). Anyone on your network or anyone who manages to insert themselves into the path between you and the Xunlei update server will be able to manipulate the server response. As a result, the application will install a malicious plugin without you even noticing anything.
You also better don’t run Xunlei Accelerator on a computer that you share with other people. Anyone on a shared computer will be able to add malicious components to the Xunlei application, so next time you run it your user account will be compromised.
Example scenario: XLServicePlatformI decided to focus on XLServicePlatform because, unlike all the other plugin management systems, this one runs with system privileges. That’s because it’s a system service and any installed plugins will be loaded as dynamic libraries into this service process. Clearly, injecting a malicious plugin here would result in full system compromise.
The management service downloads the plugin configuration from http://plugin.pc.xunlei.com/config/XLServicePlatform_12.0.3.xml. Yes, no TLS encryption here because the “HTTP client” in question isn’t capable of TLS. So anyone on the same WiFi network as you for example could redirect this request and give you a malicious response.
In fact, that HTTP client was rather badly written, and I found multiple Out-of-Bounds Read vulnerabilities despite not actively looking for them. It was fairly easy to crash the service with an unexpected response.
But it wasn’t just that. The XML response was parsed using libexpat 2.1.0. With that version being released more than ten years ago, there are numerous known vulnerabilities, including a number of critical remote code execution vulnerabilities.
I generally leave binary exploitation to other people however. Continuing with the high-level issues, a malicious plugin configuration will result in a DLL or EXE file being downloaded, yet it won’t run. There is a working security mechanism here: these files need a valid code signature issued to Shenzhen Thunder Networking Technologies Ltd.
But it still downloads. And there is our old friend: a path traversal vulnerability. Choosing the file name ..\XLBugReport.exe for that plugin will overwrite the legitimate bug reporter used by the Xunlei service. And crashing the service with a malicious server response will then run this trojanized bug reporter, with system privileges.
My proof of concept exploit merely created a file in the C:\Windows directory, just to demonstrate that it runs with sufficient privileges to do it. But we are talking about complete system compromise here.
The (lack of?) fixesAt the time of writing, XLServicePlatform still uses its own HTTP client to download plugins which still doesn’t implement TLS support. Server responses are still parsed using libexpat 2.1.0. Presumably, the Out-of-Bounds Read and Path Traversal vulnerabilities have been resolved but verifying that would take more time than I am willing to invest.
The application will still render its directory writable for all users. It will also produce a number of unencrypted HTTP requests, including some that are related to downloading application components.
Outdated componentsI’ve already mentioned the browser being based on an outdated Chromium version, the main application being built on top of an outdated Electron platform and a ten years old XML library being widely used throughout the application. This isn’t by any means the end of it however. The application packages lots of third-party components, and the general approach appears to be that none of them are ever updated.
Take for example the media player XMP a.k.a. Thunder Video which is installed as part of the application and can be started via a thunderx:// address from any website. This is also an Electron-based application, but it’s based on an even older Electron 59.0.3071.115 (released in June 2017). The playback functionality seems to be based on the APlayer SDK which Xunlei provides for free for other applications to use.
Now you might know that media codecs are extremely complicated pieces of software that are known for disastrous security issues. That’s why web browsers are very careful about which media codecs they include. Yet APlayer SDK features media codecs that have been discontinued more than a decade ago as well as some so ancient that I cannot even figure out who developed them originally. There is FFmpeg 2021-06-30 (likely a snapshot around version 4.4.4), which has dozens of known vulnerabilities. There is libpng 1.0.56, which was released in July 2011 and is affected by seven known vulnerabilities. Last but not least, there is zlib 1.2.8-4 which was released in 2015 and is affected by at least two critical vulnerabilities. These are only some examples.
So there is a very real threat that Xunlei users might get compromised via a malicious media file, either because they were tricked into opening it with Xunlei’s video player, or because a website used one of several possible ways to open it automatically.
As of Xunlei Accelerator 12.0.8.2392, I could not notice any updates to these components.
Reporting the issuesReporting security vulnerabilities is usually quite an adventure, and the language barrier doesn’t make it any better. So I was pleasantly surprised to discover XunLei Security Response Center that was even discoverable via an English-language search thanks to the site heading being translated.
Unfortunately, there was a roadblock: submitting a vulnerability is only possible after logging in via WeChat or QQ. While these social networks are immensely popular in China, creating an account from outside China proved close to impossible. I’ve spent way too much time on verifying that.
That’s when I took a closer look and discovered an email address listed on the page as fallback for people who are unable to log in. So I’ve sent altogether five vulnerability reports on 2023-12-06 and 2023-12-07. The number of reported vulnerabilities was actually higher because the reports typically combined multiple vulnerabilities. The reports mentioned 2024-03-06 as publication deadline.
I received a response a day later, on 2023-12-08:
Thank you very much for your vulnerability submission. XunLei Security Response Center has received your report. Once we have successfully reproduced the vulnerability, we will be in contact with you.
Just like most companies, they did not actually contact me again. I saw my proof of concept pages being accessed, so I assumed that the issues are being worked on and did not inquire further. Still, on 2024-02-10 I sent a reminder that the publication deadline was only a month away. I do this because in my experience companies will often “forget” about the deadline otherwise (more likely: they assume that I’m not being serious about it).
I received another laconic reply a week later which read:
XunLei Security Response Center has verified the vulnerabilities, but the vulnerabilities have not been fully repaired.
That was the end of the communication. I don’t really know what Xunlei considers fixed and what they still plan to do. Whatever I could tell about the fixes here has been pieced together from looking at the current software release and might not be entirely correct.
It does not appear that Xunlei released any further updates in the month after this communication. Given the nature of the application with its various plugin systems, I cannot be entirely certain however.